MySQL · 性能优化 · Undo Log IO优化
Author: 巴彦
背景
目前undo log读取有这么几个方面:旧版本数据读取;purge时扫描undo log record;崩溃恢复时扫描undo log record;大事务回滚。 目前线上关于undo log遇到这样两个case:
- 一个实例在崩溃重启恢复时;由于有一个特别大的活跃事务存在,读取undo log花费了数十小时才恢复。
- 线上发现某些实例的history_list特别长,一直无法降下来;定位发现,undo purge时,扫描undo records的速度太慢,导致undo整体purge速度变慢。
- 线上在kill掉一个大事务的时候,回滚会耗时。
解决方案
针对第一个问题,我们开始想:因为重启时扫描undo log record只是为了读取其中的table id,所以如果把这些table id记录到一个undo page中;那么崩溃重启恢复时就不用再去扫描其他undo log record。
针对第二个问题,我们开始想把一个trx用到的所有undo page no记录到一个数据结构中(如vector);等需要purge时,对这些undo page下发预读请求,加快读取速度。
针对第三个问题,就是扫描undo log record太慢导致回滚速度太慢。
虽然看似解决了上面三个问题;但是究其根本,还是因为读取undo page太慢的原因导致读取undo log太慢;所以我们又想出一种方案可以同时解决上面两个问题:
现在我们没有办法对undo page进行预读,是因为TRX_UNDO_PAGE_LIST 是存储在文件中;只有读取了当前的page,才知道下一个undo page在何处;所以我们设计了一个方案,在一个undo page中同时存储了这个page在TRX_UNDO_PAGE_LIST前面几个和后面几个page的位置;这样我们在读取这个page时,就可以对这个page后面几个或前面几个page进行预读;详细设计如下。
具体设计
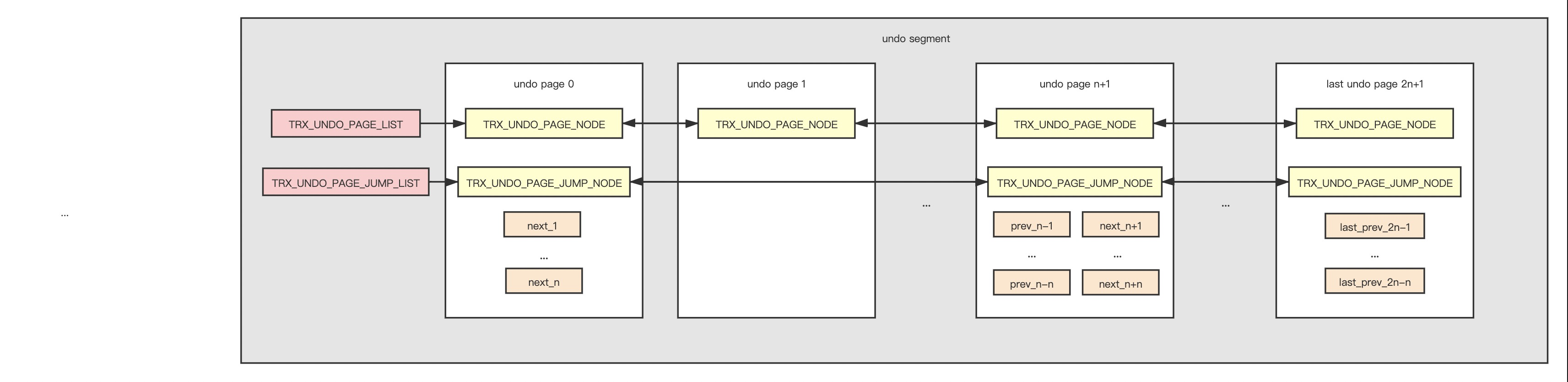
详细实现如下: 假设我们现在每次预读的page数为 n。 首先新增两个数据结构
- 新增一个数据结构(如vector),记录TRX_UNDO_PAGE_LIST之前的undo page no,设为vec1。
- 当把TRX_UNDO_PAGE_JUMP_NODE加到TRX_UNDO_PAGE_JUMP_LIST时,把此page设为cur_page_1。
具体流程如下:
- 当新申请一个undo page中时,判断 length(TRX_UNDO_PAGE_LIST)%n == 0
- 如果不满足上述条件
- 把此page加入到TRX_UNDO_PAGE_LIST中。
- 如果cur_page_1不为空,把此page no记录到cur_page_1中 next 字段中。
- 把page no记录到vec1中。
- 如果满足上述条件
- 把此page加入到TRX_UNDO_PAGE_LIST中。
- 把此page加入到TRX_UNDO_PAGE_JUMP_LIST中。
- 如果vec1不为空,把vec1中的数据记录到当前page中的 prev 字段中,并清空vec1。
- 更新 cur_page_1 为当前 page。
- 如果不满足上述条件
如何使用TRX_UNDO_PAGE_JUMP_LIST?
- 从前往后遍历时,如果TRX_UNDO_PAGE_JUMP_NODE为空,那么只读取当前page;如果TRX_UNDO_PAGE_JUMP_NODE不为空,那么除了读取当前page,把page中的所有next都下发预读请求。从后往前遍历时流程类似,只不过预读的是prev。
关于undo page的删除 关于undo page从TRX_UNDO_PAGE_LIST删除只有三种情况:
- 当当前undo page记录不下当前trx的undo log records时,需要把此undo page从TRX_UNDO_PAGE_LIST中删除;此时如果TRX_UNDO_PAGE_JUMP_NODE不为空,也应把TRX_UNDO_PAGE_JUMP_NODE从TRX_UNDO_PAGE_JUMP_LIST中删除。因为这种情况只可能发生在最新的一个undo page上,所以不会影响TRX_UNDO_PAGE_JUMP_LIST的结构。
- 崩溃恢复时,需要对trx进行回滚;回滚完的trx,要对其 undo log进行truncate,这种情况也是从后往前删;和上面的情况类似,不会影响TRX_UNDO_PAGE_JUMP_LIST的结构。
- 对rseg进行truncate时,这种情况是已经提交trx的undo log会被全部清理,也没有什么影响。
关于 n 的取值 n的取值涉及到undo log读取速度;undo page预留空间空间的问题; 原则上我们希望尽可能的提高undo log读取速度的同时,尽可能的减少对undo page的占用。 所以具体效果需要测试;查看n在不同取值时,对undo log读取速度,和undo page空间占用的影响。
兼容性的问题 在undo page中,我们需要通过一个字段来判断这个undo page是新版本的,还是旧版本的; 我们了解到,在undo log segment header中的字段,其中TRX_UNDO_STATE字段的内容其实用一个byte就可以存储,但是却分配了2个byte;所以我们用第二个byte来标记这个undo log是不是新版本的,取名为TRX_UNDO_NEW。 所以当启动实例时如果TRX_UNDO_NEW值为0,则采取老版本undo log格式来解析,否则用新版本格式来解析。 但是尽管这样,我们解决也仅仅解决了向下兼容的问题,无法解决向上兼容的问题:如果用一个老版本实例来读取新版本的undo log则会发生crash。
测试效果
| 场景 | 插入耗时 | 更新耗时 | 恢复时间 | |
|---|---|---|---|---|
| upstream | 1 hour 50 min 27.04 sec | 12 hours 48 min 28.16 sec | 849s | |
| read_ahead_pages=2 | 1 hour 25 min 43.66 sec | 12 hours 41 min 50.84 sec | 627s | |
| read_ahead_pages=4 | 1 hour 53 min 48.22 sec | 12 hours 19 min 15.08 sec | 477s | |
| read_ahead_pages=6 | 2 hours 1 min 28.73 sec | 12 hours 50 min 51.06 sec | 382s | |
| read_ahead_pages=8 | 3 hours 3 min 58.53 sec | 12 hours 44 min 46.06 sec | 320s |
从上面的测试结果来看,在使用了这个方案来优化了undo log IO后;大事务场景下,crash recovery的时间有了非常明显的提升,但是随着read ahead page的增多,插入时间有着明显的增加;所以在使用时,我们兼顾插入耗时,和undo log磁盘的消耗,可以设置read_ahead_pages = 4或者read_ahead_pages = 6来使用。