PgSQL · 特性介绍 · 列存元数据扫描介绍
Author: 雅悯
摘要
本文通过对于阿里云分析型数据库HybridDB for postgresql 数据库的列存扫描的优化特征的解析,让大家了解列存元数据扫描是如何达到提升查询扫描的速度的效果。从而使的分析型查询执行时间进一步缩短。最终能够更好的为阿里云的用户提供更高性价比的服务。
关键字
Meta data scan,HybridDB for postgresql, GreenPlum,column store,MPP 元数据扫描,列存
一、前言
人类社会已经进入了大数据时代,在这个时代人们置身于数据的海洋里,谁能够比别人更好,更有效率的, 将对自己有用的数据提取出来,谁就能更有力的获得先机,通过对数据的处理分析,来达到对未来的决策。可以毫不夸张的说,谁能够更准确,更快的掌握数据,谁就能够领先他人。
分析型数据库就是对人们已经掌握的数据,进行分析汇总,实时计算并输出结果供人们在做决策的时候进行参考或者回顾。目前人们对于分析型数据库的要求越来越高,希望它能够处理越来越大规模的数据量,但是处理时间能够越来越短。正是基于这样的需求,分析型数据库的数据处理能力的提升便成为我们数据库内核研发人员的永恒的话题。
这篇文章,我们将为大家介绍分析型数据库提升扫描能力的一个特征:元数据扫描,通过对列存储格式的数据表增加元数据信息,从而达到提升数据扫描速度的效果。在第2部分,为大家简单介绍一下元数据扫描的原理与技术实现; 第3部分,为大家介绍元数据存储的设计原理与实现;第4部分为大家介绍 元数据扫描逻辑的设计原理与实现;第5部分,提供给大家一下性能测试的结果供大家参考。第6部分,为大家介绍一下后续我们还可以持续优化的部分。
二、 元数据扫描简介
所谓元数据扫描,就是通过对数据表增加额外的信息,从而在扫描数据的时候先利用这部分数据对整个扫描数据集进行粗力度的过滤,达到减少扫描数据表的IO总量,提升扫描效率的目标。
元数据扫描可以看为是一种比索引需要更低的维护成本,在某些场景中超越纯索引扫描或者纯数据表扫描的一种扫描模式。为什么元数据扫描拥有这些优点呢? 1,首先元数据收集不需要完全精确,只需要收集一个集合元组在某一列上的最大,最小值(其中,最大,最小值可以是这一列上现有的值,也可以是不存在的值,当元组对应列值已被删除或被修改,只要原来所表示的最大,最小值范围仍然可以覆盖这一集合元组的最大,最小值,则我们不需要修改集合范围信息)。 2,使用元数据扫描可以达到索引的效果,对于数据的过滤有提升的作用,同时他对于相对返回结果较大的扫描(分析型数据扫描)又能够优于全表扫描的效果。
元数据扫描还可以对与条件的过滤采取不同的算法,可以进一步提升过滤效率,这块内容我们会在以后的文章中给大家介绍。
三、元数据扫描存储设计与实现
为了达到元数据扫描过滤的高过滤能力,我们在元数据扫描的存储设计上采用了两层结构的设计,何为两层存储结构?
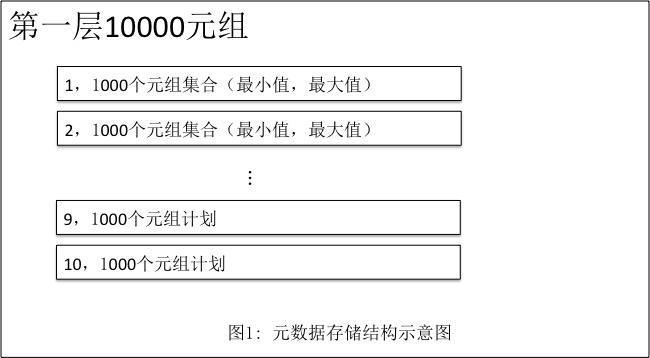
- 两层存储结构就是首先以一万个元组为第一层,收集最大值,最小值
- 在这一万个元组中,每1000个元组最为一个集合,单独收集这个集合中相应列的最大值,最小值。
这样设计为什么能够提升过滤能力?首先我们对整个10000个元组进行条件应用,如果不满足,则直接过滤掉这10000个元组。如果满足条件,我们在将这10000个元组划分为10个组,再对这10个组进行条件过滤,最大程度的减少实际扫描的数据量。数据存储示意图如图1显示:
四、元数据扫描扫描逻辑设计于实现
收集完元数据之后,我们就要利用元数据信息在查询中获得性能的提升,那么如何在原来的列存扫描逻辑中应用元数据扫描逻辑呢?
1, 首先我们需要判断是否使用元数据扫描?
a) 参数rds_enable_cs_enhancement为on;
b) 参数rds_enable_column_meta_scan为on;
c) 元数据已经被收集;
d) 查询中含有条件过滤(目前只支持部分条件的元数据扫描,后面会详细介绍),如果查询无过滤条件,也不会应用元数据扫描;
2, 当我们选择使用元数据扫描之后,我们将会按照如下逻辑进行元数据扫描准备工作。
a) 首先在表查询条件中选择可以下推的条件;
i. 目前我们只支持数据类型与字符类型数据;
ii. 简单比较操作符条件的下推(<, > , = );
iii. 不支持OR条件的下推;
iv. 字符串类型我们只支持 = 操作符下推;
b) 对条件进行解析构造新的满足元数据扫描的新的条件;
我们将原生条件分为以下几类,分别生成新的过滤条件供元数据扫描使用;其中col表示元组某一个列,colmin, colmax表示该列在某一个元数据集合中的最小值与最大值。
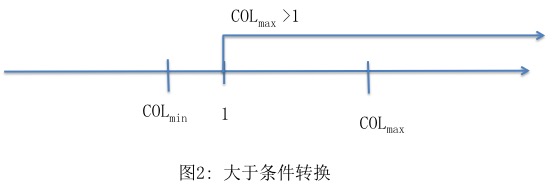
i. col > 1 转换为 colmax > 1
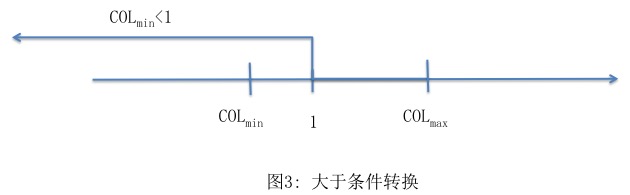
 ii. col < 1 转换为 colmin <1
ii. col < 1 转换为 colmin <1
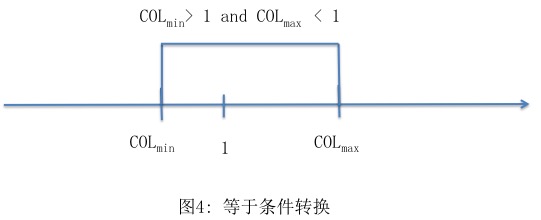
 iii. col = 1 转化为 colmin >1 and colmax <
iii. col = 1 转化为 colmin >1 and colmax <
 c) 读取元数据信息并拼装成元数据tuple;
这里拼装好新的元数据tuple之后,我们建立好colmin与colmax的在元数据tuple的位置关系与之前我们构造的过滤条件列的对应关系,然后使用数据库自带的条件判断逻辑进行条件过滤。
c) 读取元数据信息并拼装成元数据tuple;
这里拼装好新的元数据tuple之后,我们建立好colmin与colmax的在元数据tuple的位置关系与之前我们构造的过滤条件列的对应关系,然后使用数据库自带的条件判断逻辑进行条件过滤。
d) 在找到满足条件的元数据集合之后,定位到数据文件的对应位置;
直接根据元数据信息过滤后的记录号,定位到相应的实际数据文件相对应的位置开始扫描。
五、测试结果
我们选择了一些scan耗时占比较大的查询来进行测试,我们选出Q3, Q6, Q7, Q11, Q12, Q14, Q15, Q19, Q20,这几个查询。进行测试。
- 挑选出scan耗费时间相对较长的查询进行测试;
在这次测试中,我们还针对第一轮测试性能未能提升的结果,得到了一个推论,原生数据可能分布比较均匀,Meta scan过滤没有起到作用,因此我们分析了以上选取的查询,将lineitem表数据按照字段L_SHIPDATE排序,这样我们的meta信息将会更好的过滤数据。下面我们利用第二轮测试来验证我们的分析。
测试结果如图:
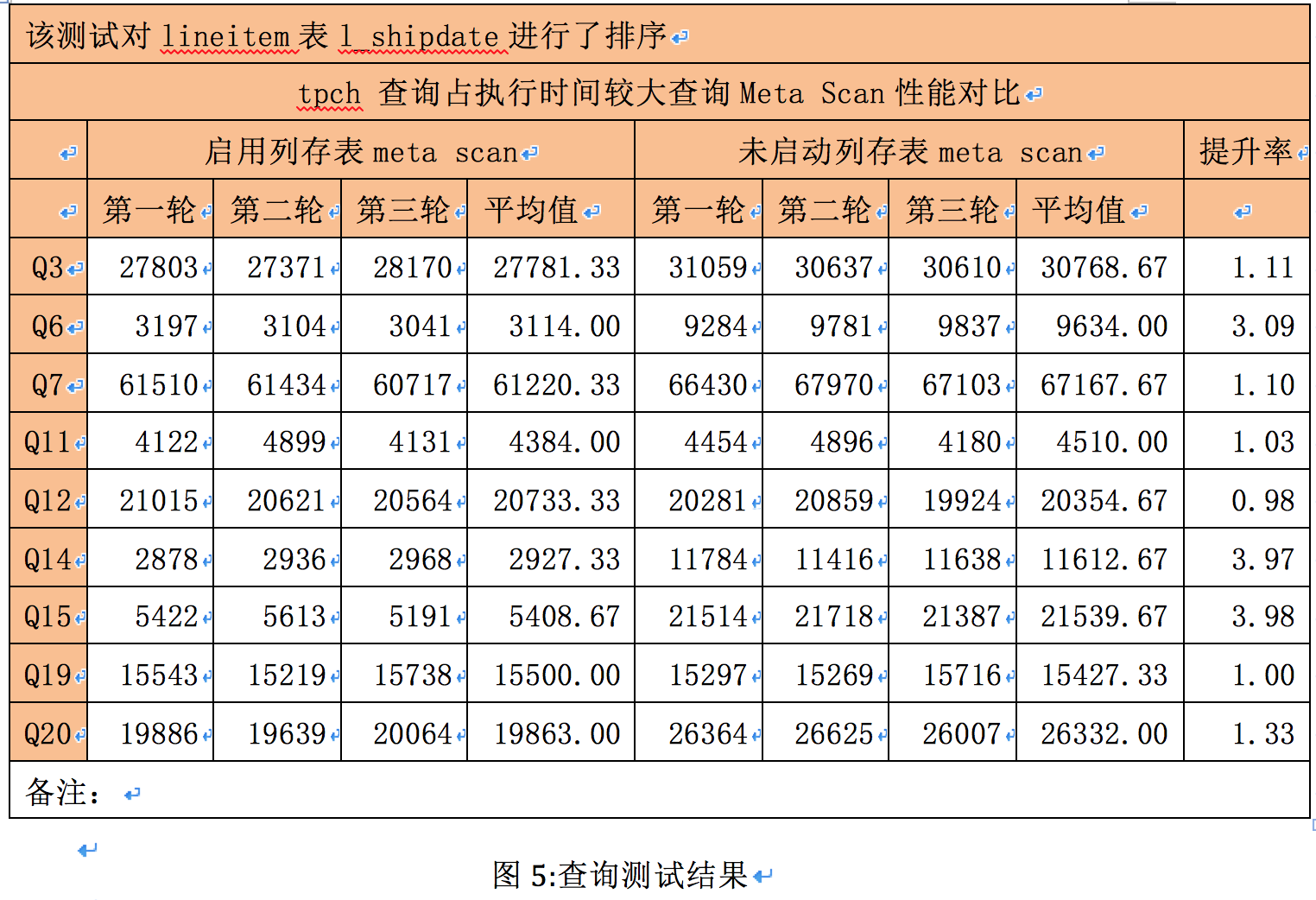
我们构筑图标连对比结果:
Q12, Q19 因为过滤条件没有l_shipdate,其他字段过滤效率同样取决于这些字段的分布状态。总结一下,Meta scan要发挥最大作用,最好谓词上每个block的数据相对有序。并且返回结果集最好较全量数据有较大缩小。
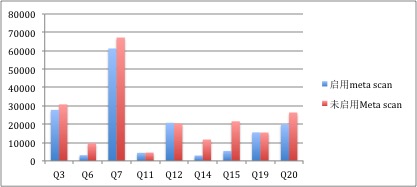
- 比对scan部分提升结果;
接着我们来看看scan部分的性能提升数据如图:
 从上图上来看,scan提升的幅度普遍大于,查询性能整体提升的幅度,这说明scan的时间占查询总时间比越大,meta scan可以发挥作用的空间就越大。
从上图上来看,scan提升的幅度普遍大于,查询性能整体提升的幅度,这说明scan的时间占查询总时间比越大,meta scan可以发挥作用的空间就越大。
六、 总结与后续工作
元数据扫描作为列存扫描方式的优化补充,对于当前OLAP分析型查询的优化具有比较好的扫描提升效果。后续我们将继续对元数据扫描在文件定位方面进行优化。