MySQL · 引擎特性 · TokuDB hot-index机制
Author: 如泽
所谓hot-index就是指在构建索引的过程中不会阻塞查询数据,也不会阻塞修改数据(insert/update/delete)。在TokuDB的实现中只有使用“create index“方式创建索引的情况下才能使用hot-index;如果使用“alter table add index”是会阻塞更新操作的。
TokuDB handler的ha_tokudb::store_lock判断是create index方式创建索引并且只创建一个索引会把lock_type改成TL_WRITE_ALLOW_WRITE,这是一个特殊的锁类型,意思是在执行写操作的过程允许其他的写操作。
TokuDB提供了session变量tokudb_create_index_online,在线开启或者关闭hot-index功能。
THR_LOCK_DATA* *ha_tokudb::store_lock(
THD* thd,
THR_LOCK_DATA** to,
enum thr_lock_type lock_type) {
if (lock_type != TL_IGNORE && lock.type == TL_UNLOCK) {
enum_sql_command sql_command = (enum_sql_command) thd_sql_command(thd);
if (!thd->in_lock_tables) {
if (sql_command == SQLCOM_CREATE_INDEX &&
tokudb::sysvars::create_index_online(thd)) {
// hot indexing
share->_num_DBs_lock.lock_read();
if (share->num_DBs == (table->s->keys + tokudb_test(hidden_primary_key))) {
lock_type = TL_WRITE_ALLOW_WRITE;
}
share->_num_DBs_lock.unlock();
} else if ((lock_type >= TL_WRITE_CONCURRENT_INSERT &&
lock_type <= TL_WRITE) &&
sql_command != SQLCOM_TRUNCATE &&
!thd_tablespace_op(thd)) {
// allow concurrent writes
lock_type = TL_WRITE_ALLOW_WRITE;
} else if (sql_command == SQLCOM_OPTIMIZE &&
lock_type == TL_READ_NO_INSERT) {
// hot optimize table
lock_type = TL_READ;
}
}
lock.type = lock_type;
}
}
代码逻辑如下图所示:
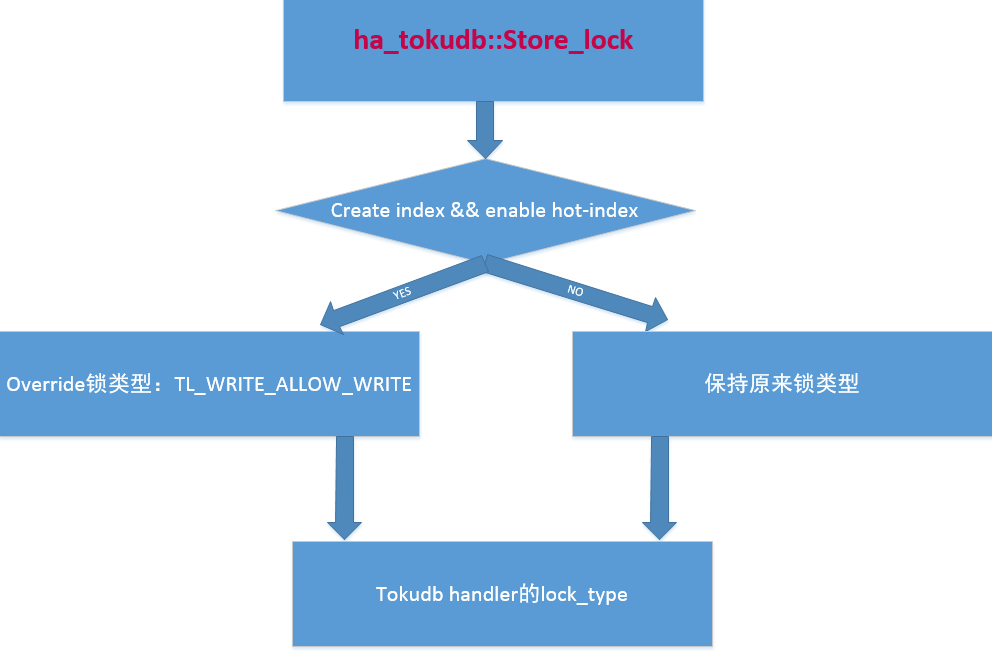
ha_tokudb::tokudb_add_index是负责创建索引的方法。这个函数首先会判断如下条件:如果同时满足以下三个条件就会走到hot-index的逻辑,否则是传统的创建索引过程。
- 锁类型是TL_WRITE_ALLOW_WRITE
- 只创建一个索引
- 不是unique索引
int ha_tokudb::tokudb_add_index(
TABLE* table_arg,
KEY* key_info,
uint num_of_keys,
DB_TXN* txn,
bool* inc_num_DBs,
bool* modified_DBs) {
bool use_hot_index = (lock.type == TL_WRITE_ALLOW_WRITE);
creating_hot_index =
use_hot_index && num_of_keys == 1 &&
(key_info[0].flags & HA_NOSAME) == 0;
if (use_hot_index && (share->num_DBs > curr_num_DBs)) {
//
// already have hot index in progress, get out
//
error = HA_ERR_INTERNAL_ERROR;
goto cleanup;
}
TokuDB目前只支持一个hot-index,也就是说同时只允许有一个hot-index在进行。如果hot-index过程中有新的创建索引操作会走传统的建索引逻辑。
传统的创建索引的方式是利用loader机制实现的,关于loader部分(点击这里跳转到原文)里面有比较详细的描述。
hot-index设计思路
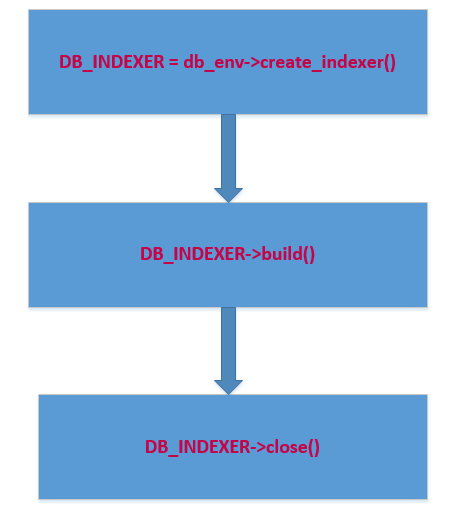
对于是hot-index方式,首先通过调用db_env->create_index接口创建一个hot-index的handle,然后通过这个handle调用build方法构建索引数据,最后是调用close方法关闭handle。
大致过程如下:
int ha_tokudb::tokudb_add_index(
TABLE* table_arg,
KEY* key_info,
uint num_of_keys,
DB_TXN* txn,
bool* inc_num_DBs,
bool* modified_DBs) {
// 省略前面部分代码
if (creating_hot_index) {
share->num_DBs++;
*inc_num_DBs = true;
error = db_env->create_indexer(
db_env,
txn,
&indexer,
share->file,
num_of_keys,
&share->key_file[curr_num_DBs],
mult_db_flags,
indexer_flags);
if (error) {
goto cleanup;
}
error = indexer->set_poll_function(
indexer, ha_tokudb::tokudb_add_index_poll, &lc);
if (error) {
goto cleanup;
}
error = indexer->set_error_callback(
indexer, ha_tokudb::loader_add_index_err, &lc);
if (error) {
goto cleanup;
}
share->_num_DBs_lock.unlock();
rw_lock_taken = false;
#ifdef HA_TOKUDB_HAS_THD_PROGRESS
// initialize a one phase progress report.
// incremental reports are done in the indexer's callback function.
thd_progress_init(thd, 1);
#endif
error = indexer->build(indexer);
if (error) {
goto cleanup;
}
share->_num_DBs_lock.lock_write();
error = indexer->close(indexer);
share->_num_DBs_lock.unlock();
if (error) {
goto cleanup;
}
indexer = NULL;
}
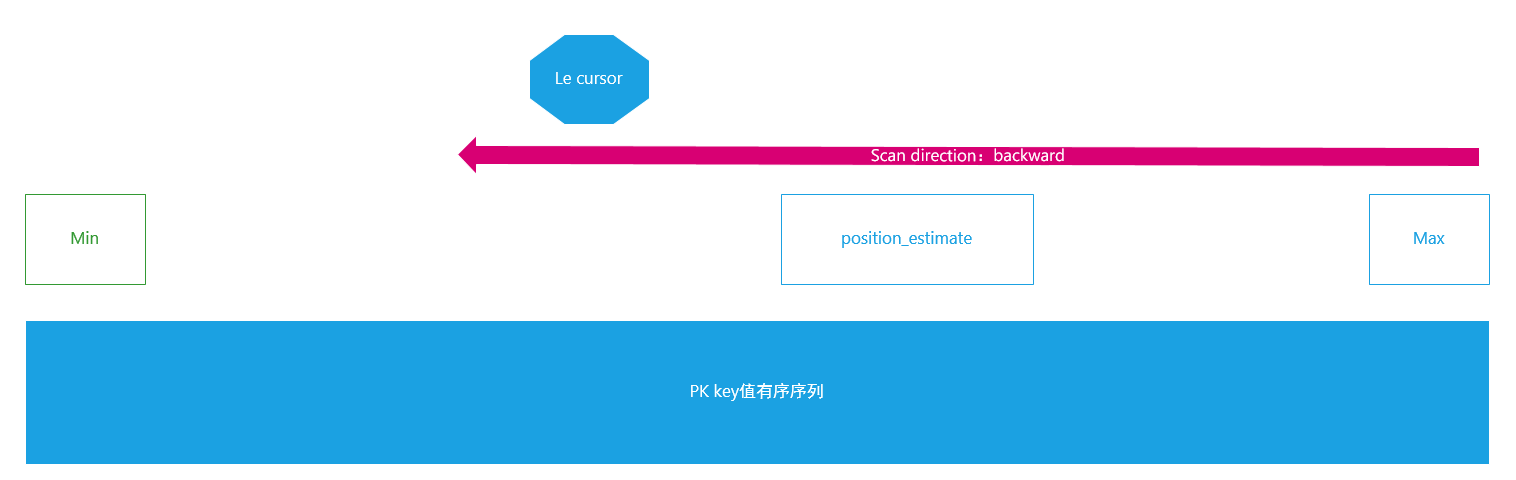
build设计思想是通过遍历pk构造二级索引。在pk上创建一个le cursor,这个cursor特别之处是读取的是MVCC结构(即leafentry)而不是数据。Le cursor遍历的方向是从正无穷(最大的key值)向前访问,一直到负无穷(最小的key值)。通过Le cursor的key和value(从MVCC中得到的)构造二级索引的key;通过pk MVCC中的事务信息,构建二级索引的MVCC。
创建indexer
indexer数据结构介绍
db_env->create_indexer其实就是toku_indexer_create_indexer,是在toku_env_create阶段设置的。 在create_indexer阶段,最主要工作就是初始化DB_INDEXER数据结构。
DB_INDEXER其实是一个接口类主要定义了build,close,abort等callback函数,其主体成员变量定义在struct __toku_indexer_internal里面。 DB_INDEXER定义如下:
typedef struct __toku_indexer DB_INDEXER;
struct __toku_indexer_internal;
struct __toku_indexer {
struct __toku_indexer_internal *i;
int (*set_error_callback)(DB_INDEXER *indexer, void (*error_cb)(DB *db, int i, int err, DBT *key, DBT *val, void *error_extra), void *error_extra); /* set the error callback */
int (*set_poll_function)(DB_INDEXER *indexer, int (*poll_func)(void *extra, float progress), void *poll_extra); /* set the polling function */
int (*build)(DB_INDEXER *indexer); /* build the indexes */
int (*close)(DB_INDEXER *indexer); /* finish indexing, free memory */
int (*abort)(DB_INDEXER *indexer); /* abort indexing, free memory */
};
__toku_indexer_internal定义如下所示
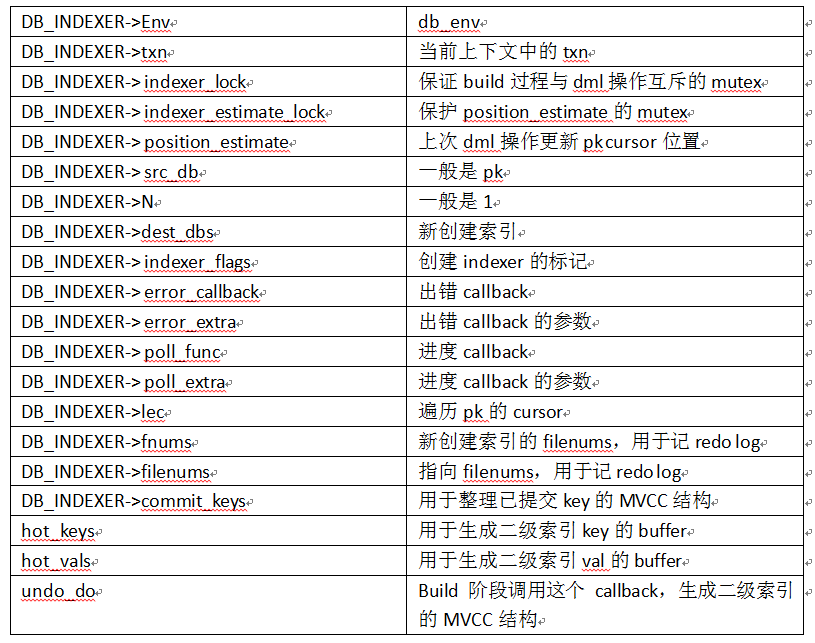
struct __toku_indexer_internal {
DB_ENV *env;
DB_TXN *txn;
toku_mutex_t indexer_lock;
toku_mutex_t indexer_estimate_lock;
DBT position_estimate;
DB *src_db;
int N;
DB **dest_dbs; /* [N] */
uint32_t indexer_flags;
void (*error_callback)(DB *db, int i, int err, DBT *key, DBT *val, void *error_extra);
void *error_extra;
int (*poll_func)(void *poll_extra, float progress);
void *poll_extra;
uint64_t estimated_rows; // current estimate of table size
uint64_t loop_mod; // how often to call poll_func
LE_CURSOR lec;
FILENUM *fnums; /* [N] */
FILENUMS filenums;
// undo state
struct indexer_commit_keys commit_keys; // set of keys to commit
DBT_ARRAY *hot_keys;
DBT_ARRAY *hot_vals;
// test functions
int (*undo_do)(DB_INDEXER *indexer, DB *hotdb, DBT* key, ULEHANDLE ule);
TOKUTXN_STATE (*test_xid_state)(DB_INDEXER *indexer, TXNID xid);
void (*test_lock_key)(DB_INDEXER *indexer, TXNID xid, DB *hotdb, DBT *key);
int (*test_delete_provisional)(DB_INDEXER *indexer, DB *hotdb, DBT *hotkey, XIDS xids);
int (*test_delete_committed)(DB_INDEXER *indexer, DB *hotdb, DBT *hotkey, XIDS xids);
int (*test_insert_provisional)(DB_INDEXER *indexer, DB *hotdb, DBT *hotkey, DBT *hotval, XIDS xids);
int (*test_insert_committed)(DB_INDEXER *indexer, DB *hotdb, DBT *hotkey, DBT *hotval, XIDS xids);
int (*test_commit_any)(DB_INDEXER *indexer, DB *db, DBT *key, XIDS xids);
// test flags
int test_only_flags;
};
db_env->create_index函数主要是初始化DB_INDEXER数据结构,这部分代码比较简单,请大家自行分析。
有一点需要提下,db_env->create_index调用toku_loader_create_loader创建一个dummy的索引。当build过程出错时,会放弃之前的所有操作,把索引重定向到那个dummy索引。这是利用loader redirect FT handle的功能,创建loader时指定LOADER_DISALLOW_PUTS标记。
构建indexer
构建indexer的函数是DB_INDEXER->build,其实调用的是build_index函数。
build_index主体是一个循环,每次去pk上读取一个key。前面提到过,访问pk是通过le cursor,每次向前访问,读取key和MVCC信息,在cursor callback把相应信息填到ule_prov_info数据结构里。le cursor的callback是le_cursor_callback,通过txn_manager得到第一个uncommitted txn信息,然后在通过那个txn的txn_child_manager得到其他的uncommitted txn信息。
在处理每个pk的key时,是受indexer->i->indexer_lock互斥锁保护的,保证build过程跟用户的dml语句互斥。build的过程还获取了multi_operation_lock读写锁的读锁。在处理当前pk值,是不允许dml和checkpoint的。对于每个pk的<key,mvcc>二元组,调用indexer_undo_do函数来构建二级索引的key和mvcc信息。下面函数中hot_keys和hot_vals是生成二级索引key和val的buffer。
struct ule_prov_info {
// these are pointers to the allocated leafentry and ule needed to calculate
// provisional info. we only borrow them - whoever created the provisional info
// is responsible for cleaning up the leafentry and ule when done.
LEAFENTRY le; //packed MVCC info
ULEHANDLE ule; //unpacked MVCC info
void* key; // key
uint32_t keylen; // key length
// provisional txn info for the ule
uint32_t num_provisional; // uncommitted txn number
uint32_t num_committed; // committed txn number
TXNID *prov_ids; // each txnid for uncommitted txn
TOKUTXN *prov_txns; // each txn for uncommited txn
TOKUTXN_STATE *prov_states; // each txn state for uncommitted txn
};
static int
build_index(DB_INDEXER *indexer) {
int result = 0;
bool done = false;
for (uint64_t loop_count = 0; !done; loop_count++) {
toku_indexer_lock(indexer);
// grab the multi operation lock because we will be injecting messages
// grab it here because we must hold it before
// trying to pin any live transactions, as discovered by #5775
toku_multi_operation_client_lock();
// grab the next leaf entry and get its provisional info. we'll
// need the provisional info for the undo-do algorithm, and we get
// it here so it can be read atomically with respect to txn commit
// and abort. the atomicity comes from the root-to-leaf path pinned
// by the query and in the getf callback function
//
// this allocates space for the prov info, so we have to destroy it
// when we're done.
struct ule_prov_info prov_info;
memset(&prov_info, 0, sizeof(prov_info));
result = get_next_ule_with_prov_info(indexer, &prov_info);
if (result != 0) {
invariant(prov_info.ule == NULL);
done = true;
if (result == DB_NOTFOUND) {
result = 0; // all done, normal way to exit loop successfully
}
}
else {
invariant(prov_info.le);
invariant(prov_info.ule);
for (int which_db = 0; (which_db < indexer->i->N) && (result == 0); which_db++) {
DB *db = indexer->i->dest_dbs[which_db];
DBT_ARRAY *hot_keys = &indexer->i->hot_keys[which_db];
DBT_ARRAY *hot_vals = &indexer->i->hot_vals[which_db];
result = indexer_undo_do(indexer, db, &prov_info, hot_keys, hot_vals);
if ((result != 0) && (indexer->i->error_callback != NULL)) {
// grab the key and call the error callback
DBT key; toku_init_dbt_flags(&key, DB_DBT_REALLOC);
toku_dbt_set(prov_info.keylen, prov_info.key, &key, NULL);
indexer->i->error_callback(db, which_db, result, &key, NULL, indexer->i->error_extra);
toku_destroy_dbt(&key);
}
}
// the leafentry and ule are not owned by the prov_info,
// and are still our responsibility to free
toku_free(prov_info.le);
toku_free(prov_info.key);
toku_ule_free(prov_info.ule);
}
toku_multi_operation_client_unlock();
toku_indexer_unlock(indexer);
ule_prov_info_destroy(&prov_info);
if (result == 0) {
result = maybe_call_poll_func(indexer, loop_count);
}
if (result != 0) {
done = true;
}
}
}
写了这么多都是framework,汗:(
indexer_undo_do函数才是build灵魂,每次调用生成二级索引的key和MVCC信息。传入参数是ule_prov_info,封装了pk的key和mvcc信息。
indexer_undo_do实现很直接,首先调用 indexer_undo_do_committed处理已提交事务对二级索引的修改,这些修改在pk上是提交的,那么在二级索引上面也一定是提交的。反复修改同一个pk会导致产生多个二级索引的key值。在pk上的体现是新值override老值;而在二级索引上就是要删老值,加新值。这也就是undo_do的意思啦。
处理committed事务时,每次处理完成都要记住新添加的二级索引的key值。最后对每个key发一个FT_COMMIT_ANY消息,整理MVCC结构,DB_INDEXER->commit_keys就是记录已提交二级索引key的,是一个数组。
int
indexer_undo_do(DB_INDEXER *indexer, DB *hotdb, struct ule_prov_info *prov_info, DBT_ARRAY *hot_keys, DBT_ARRAY *hot_vals) {
int result = indexer_undo_do_committed(indexer, hotdb, prov_info, hot_keys, hot_vals);
if (result == 0) {
result = indexer_undo_do_provisional(indexer, hotdb, prov_info, hot_keys, hot_vals);
}
if (indexer->i->test_only_flags == INDEXER_TEST_ONLY_ERROR_CALLBACK) {
result = EINVAL;
}
return result;
}
indexer_undo_do_committed函数相对简单,请大家自行分析。
下面一起看一下indexer_undo_do_provisional函数。如果num_provisional等于0,没有正在进行中的事务,直接返回。
然后依次查看每个provisional事务,uxr表示当前provisional事务的信息,包括value,txnid和delete标记。this_xid表示当前事务的txnid;this_xid_state表示当前事务的状态。
如果当前事务状态是TOKUTXN_ABORTING,啥也不用干,省得以后在root txn commit时还要再去做rollback。
条件xrindex == num_committed表示当前事务的root txn,一定把它加到xids里面;否则,意味着是子事务,只有当它处于TOKUTXN_LIVE状态时加到xids里面。xids数组是为了往FT发msg用的,表示msg所处txn上下文。
对于provisional事务,也有undo和do阶段。针对mvcc里面的nested txn,undo阶段删除old image对应的二级索引key,do阶段添加new image对应的二级索引key。这部分跟indexer_undo_do_committed类似。
只不过indexer_undo_do_provisional需要考虑最外层provisional事务(当前alive事务的root txn)的状态。
如果是TOKUTXN_LIVE或者TOKUTXN_PREPARING表名root txn正在进行中,模拟用户写索引的行为,直接调用toku_ft_maybe_delete(删除old key)或者toku_ft_maybe_insert(添加new key),这个过程是需要记undo log和redo log的,因为pk上这个事务正在进行中。
如果最外层provisional事务(当前alive事务的root txn)的状态是TOKUTXN_COMMITTING或者TOKUTXN_RETIRED表示pk上这个事务准备提交或者已经提交,直接删除old key或者添加new key,不需要记undo log和redo log,因为pk预期是提交的。
对应每个pk上面是提交的key,也需要记录下来,在结束前对每个key发FT_COMMIT_ANY消息整理MVCC结构。
release_txns函数unpin每个活跃的provisional事务,pin的过程是在toku_txn_pin_live_txn_unlocked做的;pin的目的是防止txn commit或者abort。
static int
indexer_undo_do_provisional(DB_INDEXER *indexer, DB *hotdb, struct ule_prov_info *prov_info, DBT_ARRAY *hot_keys, DBT_ARRAY *hot_vals) {
int result = 0;
indexer_commit_keys_set_empty(&indexer->i->commit_keys);
ULEHANDLE ule = prov_info->ule;
// init the xids to the root xid
XIDS xids = toku_xids_get_root_xids();
uint32_t num_provisional = prov_info->num_provisional;
uint32_t num_committed = prov_info->num_committed;
TXNID *prov_ids = prov_info->prov_ids;
TOKUTXN *prov_txns = prov_info->prov_txns;
TOKUTXN_STATE *prov_states = prov_info->prov_states;
// nothing to do if there's nothing provisional
if (num_provisional == 0) {
goto exit;
}
TXNID outermost_xid_state;
outermost_xid_state = prov_states[0];
// scan the provisional stack from the outermost to the innermost transaction record
TOKUTXN curr_txn;
curr_txn = NULL;
for (uint64_t xrindex = num_committed; xrindex < num_committed + num_provisional; xrindex++) {
// get the ith transaction record
UXRHANDLE uxr = ule_get_uxr(ule, xrindex);
TXNID this_xid = uxr_get_txnid(uxr);
TOKUTXN_STATE this_xid_state = prov_states[xrindex - num_committed];
if (this_xid_state == TOKUTXN_ABORTING) {
break; // nothing to do once we reach a transaction that is aborting
}
if (xrindex == num_committed) { // if this is the outermost xr
result = indexer_set_xid(indexer, this_xid, &xids); // always add the outermost xid to the XIDS list
curr_txn = prov_txns[xrindex - num_committed];
} else {
switch (this_xid_state) {
case TOKUTXN_LIVE:
result = indexer_append_xid(indexer, this_xid, &xids); // append a live xid to the XIDS list
curr_txn = prov_txns[xrindex - num_committed];
if (!indexer->i->test_xid_state) {
assert(curr_txn);
}
break;
case TOKUTXN_PREPARING:
assert(0); // not allowed
case TOKUTXN_COMMITTING:
case TOKUTXN_ABORTING:
case TOKUTXN_RETIRED:
break; // nothing to do
}
}
if (result != 0)
break;
if (outermost_xid_state != TOKUTXN_LIVE && xrindex > num_committed) {
// If the outermost is not live, then the inner state must be retired. That's the way that the txn API works.
assert(this_xid_state == TOKUTXN_RETIRED);
}
if (uxr_is_placeholder(uxr)) {
continue; // skip placeholders
}
// undo
uint64_t prev_xrindex;
bool prev_xrindex_found = indexer_find_prev_xr(indexer, ule, xrindex, &prev_xrindex);
if (prev_xrindex_found) {
UXRHANDLE prevuxr = ule_get_uxr(ule, prev_xrindex);
if (uxr_is_delete(prevuxr)) {
; // do nothing
} else if (uxr_is_insert(prevuxr)) {
// generate the hot delete key
result = indexer_generate_hot_keys_vals(indexer, hotdb, prov_info, prevuxr, hot_keys, NULL);
if (result == 0) {
paranoid_invariant(hot_keys->size <= hot_keys->capacity);
for (uint32_t i = 0; i < hot_keys->size; i++) {
DBT *hotkey = &hot_keys->dbts[i];
// send the delete message
switch (outermost_xid_state) {
case TOKUTXN_LIVE:
case TOKUTXN_PREPARING:
invariant(this_xid_state != TOKUTXN_ABORTING);
invariant(!curr_txn || toku_txn_get_state(curr_txn) == TOKUTXN_LIVE || toku_txn_get_state(curr_txn) == TOKUTXN_PREPARING);
result = indexer_ft_delete_provisional(indexer, hotdb, hotkey, xids, curr_txn);
if (result == 0) {
indexer_lock_key(indexer, hotdb, hotkey, prov_ids[0], curr_txn);
}
break;
case TOKUTXN_COMMITTING:
case TOKUTXN_RETIRED:
result = indexer_ft_delete_committed(indexer, hotdb, hotkey, xids);
if (result == 0)
indexer_commit_keys_add(&indexer->i->commit_keys, hotkey->size, hotkey->data);
break;
case TOKUTXN_ABORTING: // can not happen since we stop processing the leaf entry if the outer most xr is aborting
assert(0);
}
}
}
} else
assert(0);
}
if (result != 0)
break;
// do
if (uxr_is_delete(uxr)) {
; // do nothing
} else if (uxr_is_insert(uxr)) {
// generate the hot insert key and val
result = indexer_generate_hot_keys_vals(indexer, hotdb, prov_info, uxr, hot_keys, hot_vals);
if (result == 0) {
paranoid_invariant(hot_keys->size == hot_vals->size);
paranoid_invariant(hot_keys->size <= hot_keys->capacity);
paranoid_invariant(hot_vals->size <= hot_vals->capacity);
for (uint32_t i = 0; i < hot_keys->size; i++) {
DBT *hotkey = &hot_keys->dbts[i];
DBT *hotval = &hot_vals->dbts[i];
// send the insert message
switch (outermost_xid_state) {
case TOKUTXN_LIVE:
case TOKUTXN_PREPARING:
assert(this_xid_state != TOKUTXN_ABORTING);
invariant(!curr_txn || toku_txn_get_state(curr_txn) == TOKUTXN_LIVE || toku_txn_get_state(curr_txn) == TOKUTXN_PREPARING);
result = indexer_ft_insert_provisional(indexer, hotdb, hotkey, hotval, xids, curr_txn);
if (result == 0) {
indexer_lock_key(indexer, hotdb, hotkey, prov_ids[0], prov_txns[0]);
}
break;
case TOKUTXN_COMMITTING:
case TOKUTXN_RETIRED:
result = indexer_ft_insert_committed(indexer, hotdb, hotkey, hotval, xids);
// no need to do this because we do implicit commits on inserts
if (0 && result == 0)
indexer_commit_keys_add(&indexer->i->commit_keys, hotkey->size, hotkey->data);
break;
case TOKUTXN_ABORTING: // can not happen since we stop processing the leaf entry if the outer most xr is aborting
assert(0);
}
}
}
} else
assert(0);
if (result != 0)
break;
}
// send commits if the outermost provisional transaction is committed
for (int i = 0; result == 0 && i < indexer_commit_keys_valid(&indexer->i->commit_keys); i++) {
result = indexer_ft_commit(indexer, hotdb, &indexer->i->commit_keys.keys[i], xids);
}
// be careful with this in the future. Right now, only exit path
// is BEFORE we call fill_prov_info, so this happens before exit
// If in the future we add a way to exit after fill_prov_info,
// then this will need to be handled below exit
release_txns(ule, prov_states, prov_txns, indexer);
exit:
toku_xids_destroy(&xids);
return result;
}
关闭indexer
这部分就是关闭handle,释放内存。由于篇幅有限,本文不深入讨论。
与dml互斥
每个更新操作,包括insert,update和delete都要比较待处理的二级索引key是否落在已经build的部分。如果是,其处理方式跟通常的一样,直接调用db接口;否则留给hot-index来处理。
判断key是否落在已build好的部分是通过toku_indexer_should_insert_key函数比较le cursor正在处理的key和pk的key来实现的。为了避免访问le cursor的竞态,每次比较都是在indexer->i->indexer_lock保护下进行。直觉告诉我们,这个操作会影响性能,并发写可能会在indexer->i->indexer_lock上排队。
hot-index维护了le cursor大致位置indexer->i->position_estimate,这个位置是延迟更新的。每次访问le cursor比较后更新这个位置。那么,比它大的key一定落在build好的部分的。
与indexer->i->position_estimate比较的过程是不需要获取indexer->i->indexer_lock的,利用它可以做个快算判断,减少indexer->i->indexer_lock争抢。
其实,indexer->i->position_estimate更新是受indexer->i->indexer_estimate_lock保护的,这也可以算是锁拆分优化。
需要注意的是indexer->i->position_estimate和le cursor正在处理的key(更精确)都是指pk上的位置。
// a shortcut call
//
// a cheap(er) call to see if a key must be inserted
// into the DB. If true, then we know we have to insert.
// If false, then we don't know, and have to check again
// after grabbing the indexer lock
bool
toku_indexer_may_insert(DB_INDEXER* indexer, const DBT* key) {
bool may_insert = false;
toku_mutex_lock(&indexer->i->indexer_estimate_lock);
// if we have no position estimate, we can't tell, so return false
if (indexer->i->position_estimate.data == nullptr) {
may_insert = false;
} else {
DB *db = indexer->i->src_db;
const toku::comparator &cmp = toku_ft_get_comparator(db->i->ft_handle);
int c = cmp(&indexer->i->position_estimate, key);
// if key > position_estimate, then we know the indexer cursor
// is past key, and we can safely say that associated values of
// key must be inserted into the indexer's db
may_insert = c < 0;
}
toku_mutex_unlock(&indexer->i->indexer_estimate_lock);
return may_insert;
}
到这里,hot-index部分就介绍完了。代码看着复杂,但比起loader来要简单不少。