MySQL · Optimizer · Parallel Index Scans, One is Better Than Two
Author: Øystein
As presented at the Percona Live Conference in Austin in May, at Alibaba we are working on adding support for parallel query execution to POLARDB for MySQL. As discussed in the presentation, we observe that parallel range scans on secondary indexes does not scale very well in MySQL. This is old news. Mark Callaghan reported this several years ago, and this does not seem to have changed. In this blog post, I will investigate what effects using a multi-processor machine have on the scalability of parallel index range scans.
I will run a variant of Query 6 of the TPC-H/DBT-3 benchmark. While the original Query 6 sums up the revenue for a whole year, my version will only compute it over a single month:
SELECT SUM(l_extendedprice * l_discount) AS revenue
FROM lineitem
WHERE l_shipdate >= '1997-01-01'
AND l_shipdate < DATE_ADD('1997-01-01', INTERVAL '1' MONTH)
AND l_discount BETWEEN 0.05 - 0.01 AND 0.05 + 0.01
AND l_quantity < 25;
This query was run by multiple parallel threads using sysbench on MySQL 8.0.17. For each query execution, a random month was picked. The machine used have 2 processors with 16 physical cores each, so with hyper-threading there are in total 64 virtual CPUs. I used a DBT-3 scale factor 1 database, and with a 4 GB InnoDB buffer pool, all data was cached in memory. MySQL will use the secondary index on l_shipdate when executing this query. For comparison, I also ran the same query when forcing MySQL to use table scan instead of index range scan. The results are presented in this graph:
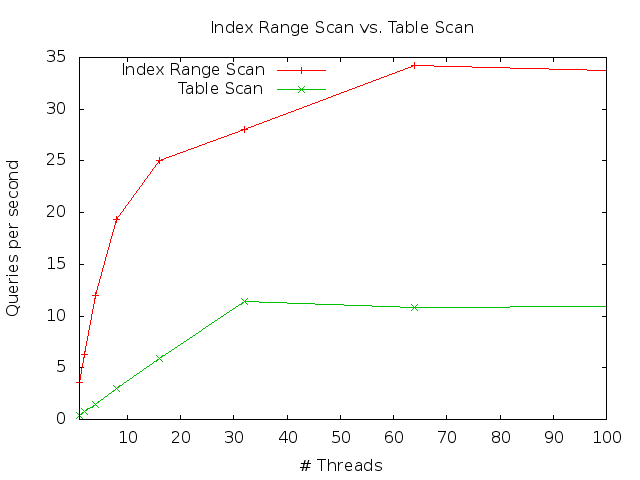
The throughput when using the secondary index is of course higher than for table scan, since we only need to read data for 1 month instead of for all 84 months when using a full table scan. However, we see that while the table scan scales almost linearly up to 32 threads, this is not the case for the index range scan. For 32 threads, the throughput with table scans is more than 30 times higher than with 1 thread. For index range scan, the increase is only about 7.8x and 9.5x for 32 and 64 threads, respectively.
We can see that for table scan, there is no benefit from hyper-threading; the maximum throughput is reached when having one thread per physical core. In other words, each thread doing table scan is able to execute without any significant interrupts. For index range scans, on the other hand, we see that we get higher throughput with 64 threads than with 32 threads. This is an indication that the threads are regularly stalled, and there is a benefit from having other threads that can be scheduled when this happens.
So why are the threads stalled? I think the most likely reason is that there is a synchronization bottleneck related to non-covering secondary index scans. Further investigations are needed to understand where, but my current guess is that it is related to accessing the root page of the B-tree when looking up the row corresponding to the index entry. (I have turned off the adaptive hash index (AHI) when running these tests, so all primary key look-ups will have to go through the root page. When using the AHI, the scaling seem to be even worse, but that is different story …)
When there is a lot of thread synchronization, running on multiple processors may increase our problems since the state of the mutex, or whatever is used for synchronization, will have to be synchronized between the caches of the CPUs. To investigate what effects this have for our case, I will use Resource Groups to make MySQL use only one processor for this query. First, I will create a resource group, cpu1, that contains the virtual CPUs of processor 1:
CREATE RESOURCE GROUP cpu1 TYPE=user VCPU=16-31,48-63;
To make our query use this resource group, we add a hint to the query:
SELECT /*+ RESOURCE_GROUP(cpu1) */
SUM(l_extendedprice * l_discount) AS revenue
FROM lineitem
WHERE l_shipdate >= '1997-01-01'
AND l_shipdate < DATE_ADD('1997-01-01', INTERVAL '1' MONTH)
AND l_discount BETWEEN 0.05 - 0.01 AND 0.05 + 0.01
AND l_quantity < 25;
We repeat the sysbench runs with this query, and compare the results for index range scans:
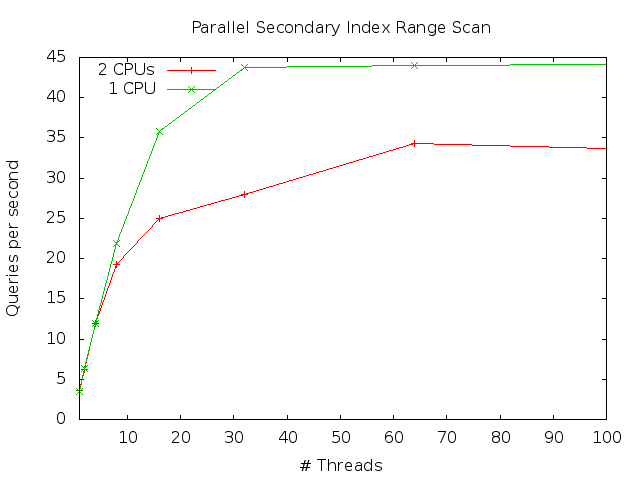
We see that using only the cores of one processor, increases the performance. The maximum throughput is increased by almost 30% by using one processor instead of two! The “scale factors” are now 10.3x and 12.6x for 16 and 32 threads, respectively. Much better, but still a bit away from perfect scaling. Hence, there is still a need for further investigations. Stay tuned!
This blog post first appeared at oysteing.blogspot.com