MySQL · 最佳实践 · 8.0 redo log写入性能问题分析
Author: songzhao.sz
对比了MySQL 5.6和8.0在8核环境下oltp_write_only的性能,发现8.0写入性能(QPS 6-7万)反而低于5.6版本的(QPS 14万),所以进一步测试分析了下redo log这里可能导致性能降低的原因
1. 测试方法
sysbench –mysql-host=IP –mysql-port=PORT –mysql-user=mysql –mysql-password=PASSWD –tables=250 –table_size=25000 –db_driver=mysql –threads=128 –report-interval=5 –rand-type=uniform prepare
sysbench –mysql-host=IP –mysql-port=PORT –mysql-user=mysql –mysql-password=PASSWD –tables=250 –table_size=25000 –db_driver=mysql –threads=128 –report-interval=5 –rand-type=uniform –max-time=360 –max-requests=3000000 run
sysbench –mysql-host=IP –mysql-port=PORT –mysql-user=mysql –mysql-password=PASSWD –table_size=25000 –db_driver=mysql –threads=128 cleanup
2. 测试结果
1. upstream 8.0 (8核)
SQL statistics:
queries performed:
read: 0
write: 12000000
other: 6000000
total: 18000000
transactions: 3000000 (10792.71 per sec.)
queries: 18000000 (64756.24 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 277.9637s
total number of events: 3000000
CPU:
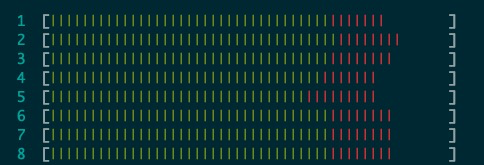
2. upstream 8.0(8核,CPU 8专门跑log_writer,其余线程跑在1-7)
SQL statistics:
queries performed:
read: 0
write: 12000000
other: 6000000
total: 18000000
transactions: 3000000 (10705.28 per sec.)
queries: 18000000 (64231.71 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 280.2336s
total number of events: 3000000
CPU:
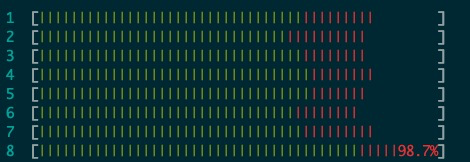
3. upstream 8.0(8核,CPU 8专门跑log_flusher,其余线程跑1-7)
SQL statistics:
queries performed:
read: 0
write: 12000000
other: 6000000
total: 18000000
transactions: 3000000 (12860.01 per sec.)
queries: 18000000 (77160.08 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 233.2794s
total number of events: 3000000
CPU:
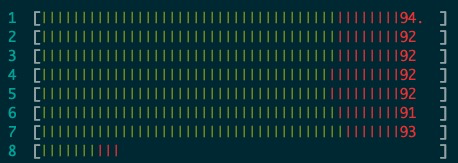
4. upstream 8.0(8核,CPU 8专门用来跑log_writer和log_flusher,其余线程跑在1-7)
SQL statistics:
queries performed:
read: 0
write: 12000000
other: 6000000
total: 18000000
transactions: 3000000 (15305.69 per sec.)
queries: 18000000 (91834.11 per sec.)
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 196.0038s
total number of events: 3000000
CPU:

3. 结果分析
- 不做任何隔离时,8核均无法跑不到100%,性能较低,QPS 64756.24
- 只隔离log_writer时,单独跑log_writer的核可以接近100%,但剩余7核不行,性能没有提升, QPS 64231.71
- 只隔离log_flusher时8核可以都大于90%,性能有所提升,QPS 77599.04
- 同时隔离log_writer和log_flusher时8核可以都接近100%,性能进一步提升,QPS 91834.11
从上面的结果可以看出来,
- log_flusher是否隔离对8核CPU利用率的影响较大,分析原因应该是在不隔离log_flusher时,由于和很多用户线程共享CPU,所以log_flusher得不到有效的CPU调度无法充分执行,flush_to_disk_lsn更新滞后反过来又影响到用户线程的推进(innodb_flush_log_at_trx_commit = 1),所以整体CPU利用率上不去。隔离log_flusher之后,CPU和性能都有所提升,但相比同时隔离log_writer和log_flusher又有低一些
- 单独隔离log_writer性能没有提升,分析原因应该还是同上,瓶颈在log_flusher上
综上,关于upstream 8.0写入性能较低的原因推测是log_writer和log_flusher由于和大量用户线程共享CPU核心,得不到充分调度成为瓶颈,影响整体写入性能,并且log_flusher更为严重。
4. 进一步验证
为了进一步验证上面的推测,我使用sysbench –max-requests=3000000分别对如下4中场景:
a.不隔离
b.同时隔离log_writer及log_flusher
c.单独隔离log_writer
d.单独隔离log_flusher
进行等量压测,每次都是300万次请求,另外为了LSN的可比较性,关掉了undo purge,基于此,我在sysbench run阶段对InnoDB log module进行打点记录,下面分组来看具体性能和打点信息:
性能
| a.不隔离 | b.隔离writer&flusher | c.隔离writer | d.隔离flusher | |
|---|---|---|---|---|
| QPS | 78739.83 | 93705.47 | 84082.08 | 81546.58 |
| TIME | 228.5992s | 192.0894s | 214.0747s | 220.7310s |
由于关掉了undo purge,除场景b外,其他场景QPS相较于之前的测试有所提升是符合预期的
打点信息
1. LSN
| a.不隔离 | b.隔离writer&flusher | c.隔离writer | d.隔离flusher | |
|---|---|---|---|---|
| log_lsn_current | 5736265204 | 5736254809 | 5736543934 | 5736474256 |
同样由于关掉了undo purge,对于sysbench –max-requests=3000000,lsn差不多
2. Buffer Wait
| a.不隔离 | b.隔离writer&flusher | c.隔离writer | d.隔离flusher | |
|---|---|---|---|---|
| log_waits | 0 | 0 | 0 | 0 |
| log_on_buffer_space_no_waits | 0 | 0 | 0 | 0 |
| log_on_buffer_space_waits | 0 | 0 | 0 | 0 |
| log_on_buffer_space_waits_loops | 0 | 0 | 0 | 0 |
上面的这4个监控信息都是
mtr_t::commit()->
mtr_t::Command::execute()->
log_buffer_reserve()->
log_wait_for_space_after_reserving()->
log_wait_for_space_in_log_buf()->
log_write_up_to(flush_to_disk=false)->
log_wait_for_write()
里的打点,它们全为0,也就是说明配置使用的64M大小log buffer是够用的,无论隔离与否,都不会出现因为log buffer不够用而进行回收时的wait
3. recent_XXX
| a.不隔离 | b.隔离writer&flusher | c.隔离writer | d.隔离flusher | |
|---|---|---|---|---|
| log_on_recent_written_wait_loops | 0 | 0 | 0 | 0 |
| log_on_recent_closed_wait_loops | 0 | 0 | 0 | 0 |
1.log_on_recent_written_wait_loops是在
mtr_t::commit()->
mtr_t::Command::execute()->
mtr_write_log_t::()->
log_buffer_write_completed()
里如果由于recent_written不足等待回收则进行的打点
2.log_on_recent_closed_wait_loops是在
mtr_t::commit()->
mtr_t::Command::execute()->
mtr_write_log_t::()->
log_wait_for_space_in_log_recent_closed()
里如果由于recent_closed不足等待回收则进行的打点
它们都为0说明recent_written和recent_closed当前配置够用,并且log_writer和log_closer对其回收及时。
重点关注下面的打点信息,首先先说下打点位置
4. Log Writes
| a.不隔离 | b.隔离writer&flusher | c.隔离writer | d.隔离flusher | |
|---|---|---|---|---|
| log_write_requests | 53837519 | 53772294 | 53987892 | 54287129 |
| log_writes | 24891146 | 22661060 | 40653491 | 4036257 |
1.log_write_requests是
mtr_t::commit()->
mtr_t::Command::execute()->
log_buffer_reserve()
里打点,可以看到mtr的个数也差不多
2.log_writes是
log_writer()->
log_writer_write_buffer()->
log_files_write_buffer()
里log_writer将log写进table cache并更新log_sys->write_lsn之后的打点
5. log_writer
| a.不隔离 | b.隔离writer&flusher | c.隔离writer | d.隔离flusher | |
|---|---|---|---|---|
| log_writer_no_waits | 24110198 | 21737096 | 38915995 | 3395741 |
| log_writer_waits | 706 | 525 | 341 | 233 |
| log_writer_wait_loops | 4505 | 4110 | 3084 | 1467 |
| log_writer_on_file_space_waits | 0 | 0 | 0 | 0 |
| log_write_notifier_no_waits | 96650 | 117586 | 141001 | 42684 |
| log_write_notifier_waits | 6364591 | 2184418 | 2405656 | 2168416 |
| log_write_notifier_wait_loops | 6702652 | 2520352 | 2439346 | 2846572 |
| log_on_write_no_waits | 0 | 0 | 0 | 0 |
| log_on_write_waits | 0 | 0 | 0 | 0 |
| log_on_write_wait_loops | 0 | 0 | 0 | 0 |
1.log_writer_no_waits和log_writer_waits都是在
log_writer()->
os_event_wait_for(log.writer_event)
后的打点,log_writer_no_waits是在os_event_wait_for()时发现有连续可写的内容不需wait的次数,log_writer_waits是在os_event_wait_for()时发现没有连续可写的内容需要wait的次数
2.log_write_notifier_no_waits和log_write_notifier_waits都是在
log_write_notifier()->
os_event_wait_for(log.write_notifier_event)
后的打点,log_writer_no_waits是在os_event_wait_for()时发现log.write_lsn向前推进所以不需wait的次数,log_write_notifier_waits是os_event_wait_for()时发现log.write_lsn没有向前推进所以需要wait的次数
3.log_on_write_no_waits和log_on_write_waits都是在
XXX->
log_write_up_to()->
log_wait_for_write()->
os_event_wait_for(log.write_events[])
后的打点,可以看到都为0,说明并不存在用户线程在等待log_writer更新log.write_lsn到指定lsn的时候。
6. log_flusher
| a.不隔离 | b.隔离writer&flusher | c.隔离writer | d.隔离flusher | |
|---|---|---|---|---|
| log_flusher_no_waits | 219898 | 4639077 | 353433 | 843696 |
| log_flusher_waits | 11126 | 201415 | 215 | 59647 |
| log_flusher_wait_loops | 205948 | 224423 | 2083 | 2797221 |
| log_flush_notifier_no_waits | 7049 | 121679 | 2944 | 62289 |
| log_flush_notifier_waits | 128905 | 950814 | 231335 | 218895 |
| log_flush_notifier_wait_loops | 980173 | 1091132 | 1059829 | 958259 |
| log_on_flush_no_waits | 760 | 8934 | 972 | 1506 |
| log_on_flush_waits | 2993605 | 2975193 | 2993935 | 2991368 |
| log_on_flush_wait_loops | 8616066 | 3011060 | 6091019 | 6954663 |
| log_flush_lsn_avg_rate | 358652 | 11395 | 234238 | 94717 |
| log_flush_total_time | 181411112us (181s) | 137893867us (138s) | 209647279us (210s) | 29879924us (30s) |
| log_flush_avg_time | 683us | 27us | 642us | 25us |
1.log_flusher_no_waits、log_flusher_waits和log_flusher_wait_loops都是在
log_flusher()->
os_event_wait_for(log.flusher_event)
后的打点,log_flusher_no_waits是在os_event_wait_for()时发现log.write_lsn向前推进所以不需要wait的次数,
log_flusher_waits是在os_event_wait_for()时发现log.write_lsn没有向前推进所以需要wait的次数,log_flusher_wait_loops则是在wait里被唤醒或timeout之后发现condition还不满足而继续wait的loop次数
2.log_flush_notifier_no_waits和log_flush_notifier_waits都是在
log_flush_notifier()->
os_event_wait_for(log.flush_notifier_event)
后的打点,log_flush_notifier_no_waits是在os_event_wait_for()时发现log.flushed_to_disk_lsn更新所以不需要wait的次数,log_flush_notifier_waits是在os_event_wait_for()时发现log.flushed_to_disk_lsn没更新所以需要wait的次数
3.log_on_flush_no_waits、log_on_flush_waits和log_on_flush_wait_loops都是在
XXX->
log_write_up_to(flush_to_disk=true)->
log_wait_for_flush()
后的打点,这里是用户线程在(innodb_flush_log_at_trx_commit = 1)等待flush_to_disk_lsn更新到自己对应的LSN,log_on_flush_no_waits是当用户线程对应的LSN的redo log已被log_flusher刷盘,无需wait的次数,log_on_flush_waits是当用户线程对应LSN的暂未不刷盘,需要wait的次数,log_on_flush_wait_loops是在wait中被唤醒或timeout后发现condition还不满足继续wait的loop次数
4.log_flush_lsn_avg_rate是每30次flush的内容平均每秒的长度
5.log_flush_total_time是整体flush的用时
6.log_flush_avg_time单次flush的平均用时
基于以上信息,分析如下,以a.不隔离作为基准
- 隔离log_flusher(场景d),可以看到隔离log_flusher之后,由于log_flusher独占1个核心,此时log_flusher_no_waits从219898增长到843696(4倍),说明log_flusher被调度执行到的次数更多,刷盘更及时,甚至因为CPU太过充分导致log_flusher_waits、log_flusher_wait_loops出现大幅增长。而log_on_flush_no_waits和log_on_flush_waits没有太大变化说明即使刷盘效率有所提高,但用户线程在自己对应LSN刷盘时还是需要等待,不过log_on_flush_wait_loops有所减少,从8616066减少到6954663,虽然wait次数没变,但wait里的loop变少,说明一定程度上用户线程推进速度还是有所提升,这点也符合QPS和CPU利用率提升的现象。另外log_flusher大约100万次(log_flusher_no_waits+log_flusher_waits)的刷盘操作,总用时30s,单次刷盘25us,效率最高。不过为什么整体性能提升有限呢?因为此时log_writer成为了瓶颈,此时CPU利用率有所提升,log_writer与大量用户线程共享核心,得不到充分调度,更新write_lsn不及时,这点可以从log_writer_no_waits和log_writes看出来,log_writer_waits没变的基础上,log_writer_no_waits从24110198降到3395741(1/6),正是因为隔离log_flusher后,用户线程CPU利用率有所提高(不隔离时会在等待自己对应LSN刷盘上wait较久,这样还会让出CPU给log_writer来用),log_writer拿不到CPU导致,对应的log_writes也从24891146降到4036257(1/6),log_writer的写入效率变低,瓶颈。
- 隔离log_writer(场景c),可以看到隔离log_writer之后,由于log_writer独占1个核心,此时log_writer_no_waits从24110198增长到38915995(近2倍),说明log_writer被调度到的次数更多,write_lsn推进更及时。而log_writer_waits没什么变化说明即使log_writer独占1个核心,CPU也是刚刚够用,基本每次写完page cache后就有新的log要再写入。不过log_on_flush_no_waits和log_on_flush_waits没有太大变化说明即使写page cache效率有所提高,但用户线程在等自己对应LSN刷盘时还是需要等待,不过log_on_flush_wait_loops有所减少,从8616066减少到6091019,一定程度上用户线程推进速度有所提升。至于整体性能提升不明显的原因,是因为此时log_flusher是瓶颈。按理说log_writer执行频率和效率大幅提高,唤醒log_flusher的频率也会很高,但log_flusher_no_waits从219898仅增长至353433(1.7倍,还不如隔离log_flusher带来的提升),log_flusher_waits甚至降低,另外可以看到log_flusher大约刷盘35万次,总用时210s,单次平均用时642us,(即使刨除由于单次fsync的内容变多导致可能的fsync用时变长之外)远高于隔离log_flusher时的用时,都说明此时log_flusher得不到有效的CPU调度,执行效率低下,瓶颈。
- 同时隔离log_writer和log_flusher(场景b),二者共用1个核心,此时log_flusher_no_waits从219898提升至4639077(23倍),被调度的更多,执行更充分,另外log_writer_no_waits没有太大变化(应该是log_flusher被调度更多了,执行效率变高,所以与其共享一个核心的log_writer相比不隔离时被调度的次数稍少一些),这样在log_writer执行效率没有太大变化的情况下,log_flusher效率大幅度提升,一共刷盘500万次,总用时138s,单次平均用时27us。这种情况,在log_on_flush_waits不变的基础上,log_on_flush_no_loops从8616066减少到3011060(1/3),用户线程在等待自己LSN落盘的wait loops减少最多,所以整体性能也提升最多。
5. 其他发现
- 在不做任何隔离的情况下,打开undo purge的性能低于关闭时的QPS,(64756.24 : 78739.83),分析原因应该是打开undo purge时,由于undo purge truncate会写入更多的log,导致LSN变大(5736265204 :7692486960),在插入这么多新的redo log后,由于log_flusher效率并没有提升,log变多了,用户线程在等待自己对应LSN刷盘时会等更久(log_on_flush_wait_loops变化,13015383 : 8616066),所以性能低一些。
- 在32核,1024并发场景下,不隔离时QPS是274509.11,隔离时(log_writer和log_flusher同时绑定在CPU32)QPS反而降为254697.57,分析了下打点数据,隔离时log_writer_no_waits从8175104将为5261245,说明当在更多核心更高压力时,将log_writer、log_flusher同时放在一个核心会因为此时log_flusher相比不隔离时刷盘更快而导致log_writer被调度执行的机会更少,log_writer成为瓶颈
- 在2的场景下,进一步测试,保持用户使用的核心数不变(CPU 1-31),多加一个核心,将log_writer绑定CPU32,log_flusher绑定CPU33,发现此时性能和不隔离是差不太多(281093.45 :274509.11),分析打点数据,此时log_writer_no_waits(11153587)和log_flusher_no_waits(1600971)都大幅提升,说明二者并不是瓶颈(另外观察到此时log_flusher所在核心的CPU利用率也都有70%左右了),但性能为什么没上去呢?发现此时log_on_recent_closed_wait_loops从之前的0变成了17844432,证明用户线程在mtr::commit时等待recent_closed buffer回收空间次数变多,应该是此时log_writer写的更快,而log_closer由于与用户线程共享CPU,回收recent_closed不及时导致的,log_closer成为新的瓶颈
- 在3的场景下,进一步测试,保持用户使用的核心数(CPU 1-31)和log_writer(CPU 32)和log_flusher(CPU32)不变的基础上,再加一个核心,绑定log_closer(CPU33),此时性能提升较多310020.40,不过此时log_on_recent_closed_wait_loops并不为0(758048),因为log_closer并不是由谁唤醒而是周期性的执行,所以在这种情况下,默认的sleep时间(1000us)也显得太久,需要调小
- 在2的场景下,只是用32个核心,用户线程使用(1-29),log_flusher、log_writer、log_closer使用(30-32),这样即使用户线程使用的核心相比场景2少了2个,但整体性能是299089.22,相比场景2反而有所提升
6. 总结
MySQL 8.0将写redo log拆分成多个线程异步来做的方式,可能并不是理想的优化,
- 当并发比较低(用户线程少)时,用户线程与这些异步线程之间的交互等待反而不如直接像RocksDB那样全有用户线程来做更核实
- 在并发比较高(用户线程多)时,又会因为这些异步线程(log_writer、log_flusher、log_closer)得不到充分的CPU调度而成为写入瓶颈。这样的异步设计需要确保这些异步线程有足够的CPU时间才能提高性能
所以目前能想到的改进方案有如下:
- 提高log异步线程的优先级