PgSQL · 新版本调研 · 13 Beta 1 初体验
Author: 卓刀
背景
从PostgreSQL 10 开始,社区保持每年一个大版本的节奏,表现出了超强的社区活力和社区创造力。
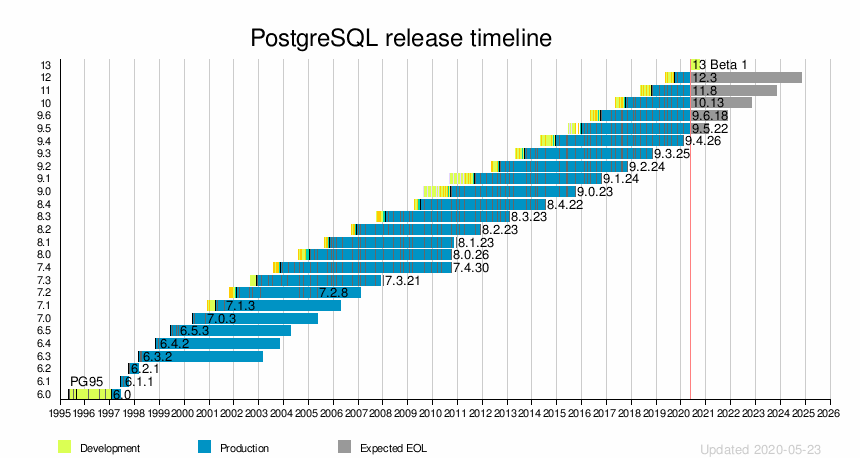
在2020-05-21 这个特殊的日子里,PostgreSQL 全球开发组宣布PostgreSQL 13 的Beta 1 正式对外开放,可提供下载。这个版本包含将来PostgreSQL 13正式版本中的所有特性和功能,当然一些功能的细节在正式版本发布时可能会有些变化。 下面我们将详细了解下PostgreSQL 13 版本新的特性和功能。
PostgreSQL 13 新增特性
在社区的对外发布的文档中,把PostgreSQL 13 的新增特性分为了几部分:
- 数据库功能相关
- 数据库运维管理相关
- 数据库安全性相关
- 其他亮点
我们也按照这几部分来详细介绍,并对一些功能做一些实际的测试,看下具体的效果。
数据库功能相关
在PostgreSQL 13 版本中有许多地方的改进来实现性能的提升,同时对应用开发人员来说,应用开发更加容易。
B树索引优化
表的列如果不是唯一的,可能会有很多相同的值,对应的B树索引也会有很多重复的索引记录。在PostgreSQL 13 中B树索引借鉴了GIN 索引的做法,将相同的Key 指向的对应行的ctid 链接起来。这样既减小了索引的大小,又减少了很多不必要的分裂,提高了索引的检索速度,我们把该优化称为B树索引的deduplicate 功能。另外,B树索引的deduplicate 功能是异步进行的,只有在B 树索引需要分裂的时候才会去做该操作,减少了该功能的日常开销。
B树索引的deduplicate 功能的使用方法如下:
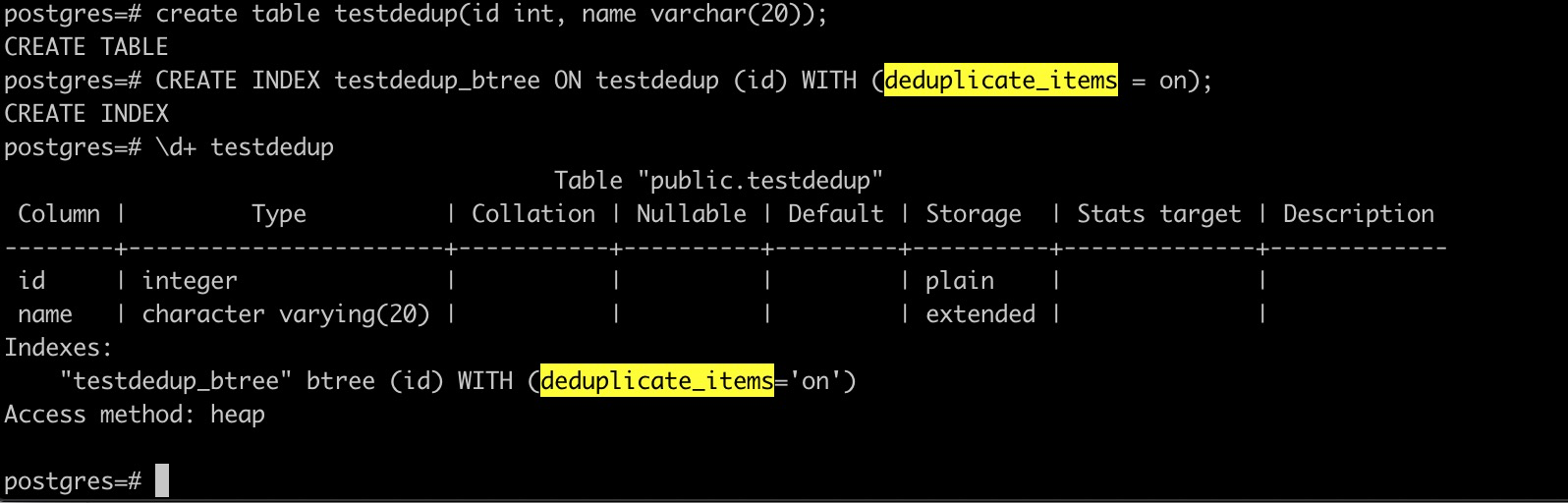
可以看出,需要在创建B 树索引的时候增加deduplicate_items 存储参数为on(PG 13 中index 该存储参数目前默认为on),deduplicate 功能才会开启。
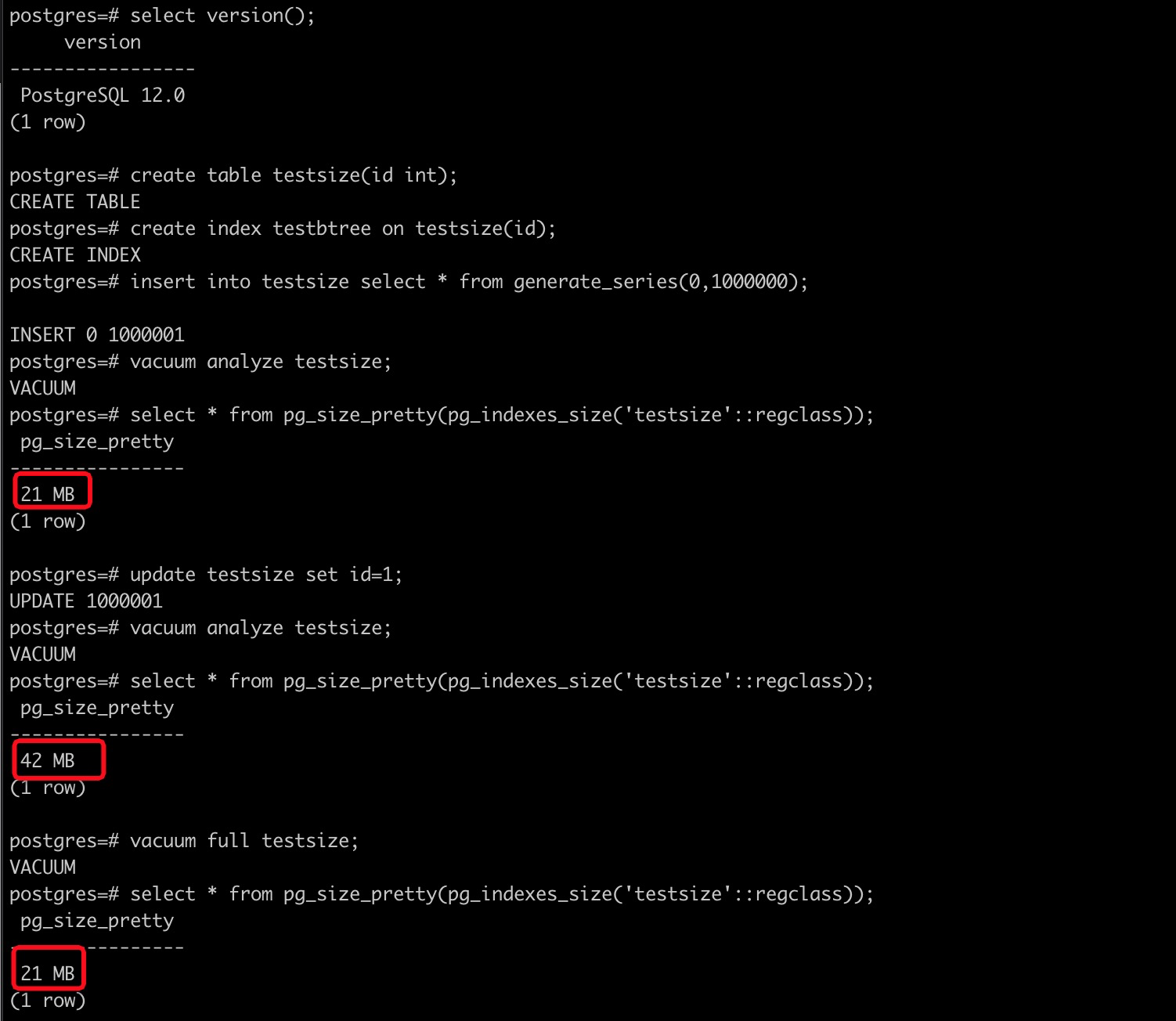
为了测试deduplicate 功能的效果,我们拿12 和13 版本做了下对比。
PostgreSQL 12 含有
 PostgreSQL 13:
PostgreSQL 13:
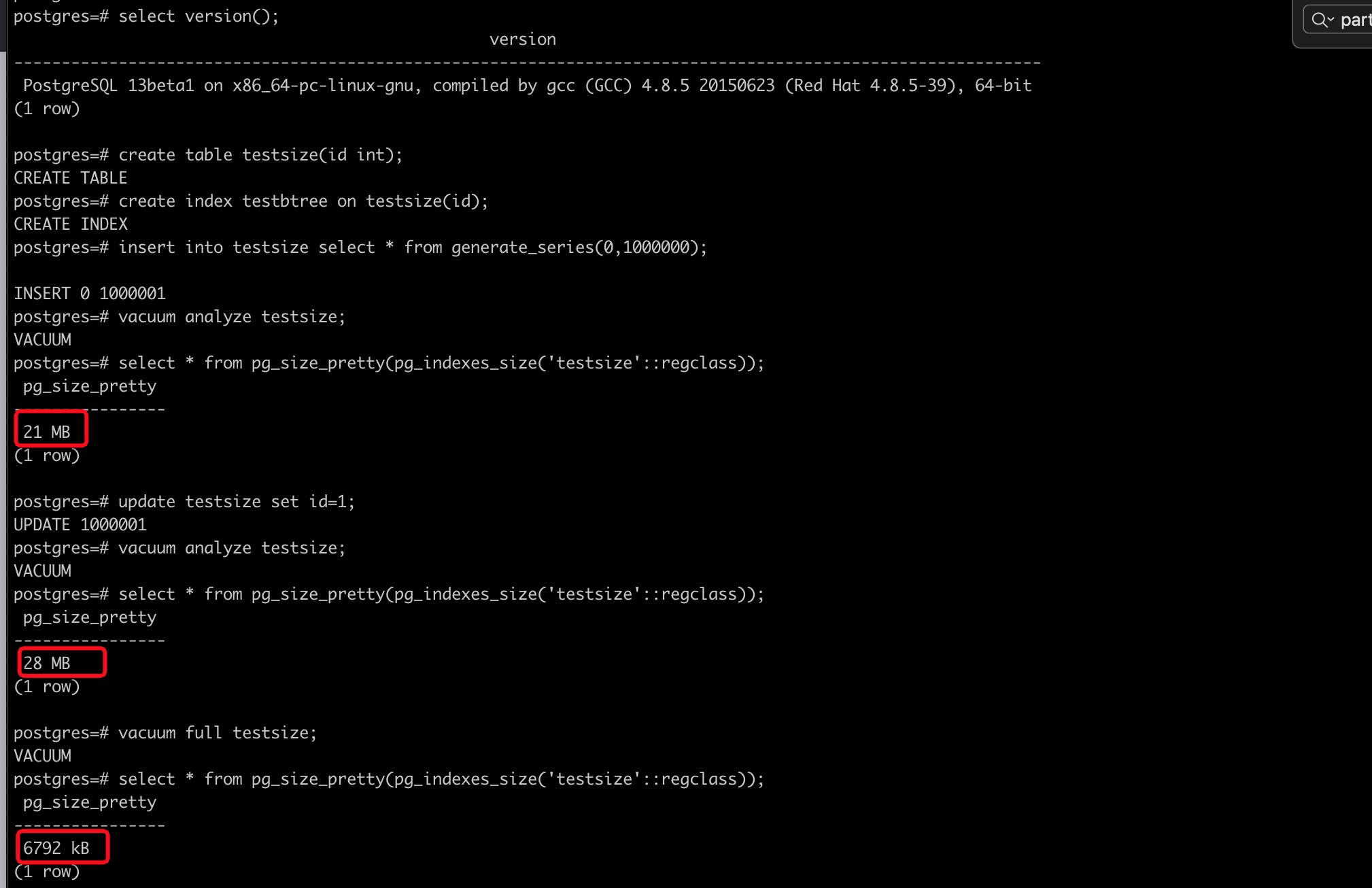
可以看出:
- PostgreSQL 13 和PostgreSQL 12相比,相同类型且没有重复值的B树索引,大小相同。
- PostgreSQL 13 和PostgreSQL 12相比,相同类型且有大量重复值的B树索引更小。
- PostgreSQL 13 和PostgreSQL 12相比,如果索引有大量重复值且执行计划走index only scan 的话,需要读取的索引页更少,效率更高。
除了数据级别的重复之外,因为PostgreSQL 的MVCC 实现会带来B树索引中有重复Key 的不同快照,13 版本中B树索引的deduplicate 功能同样对其有效。不过有一定的局限:
- text, varchar, char 类型数据,如果使用了特殊的collation,则可能需要大小写和口音不同来定义数据是否相等,无法使用deduplicate 功能。
- numeric 类型数据无法使用deduplicate 功能,因为numeric 类型需要结合不同的展示范围才能定义数值是否相等。
- jsonb 类型数据无法使用deduplicate 功能,因为jsonb B树操作类型内部使用了numeric 类型。
- float4 和float8 类型数据无法使用该优化,因为在这两个类型中-0 和0 数值被认为是相等的。
总的来说,这些不支持的数据类型主要是因为判断他们Key 是否相同不能只通过数值来判断,还需要额外的条件。
B树索引是PostgreSQL 中默认的索引类型,社区几个大版本都对其占用空间和执行效率不断地进行优化。其实,PostgreSQL 12 中已经对B 树索引做了一定的deduplicate 优化,详见之前的文章,13 版本是对该优化的进一步完善和增强。
增量排序
PostgreSQL 13 版本增加了增量排序。这个优化其实起源于一个很朴素的算法,当对一组数据集(X,Y)按照X、Y两列进行组合排序,如果当前数据集已经按X 列进行了排序,如下:
(1, 5)
(1, 2)
(2, 9)
(2, 1)
(2, 5)
(3, 3)
(3, 7)
这时,只需要对数据集按照X 分组,并在每组中对Y 列继续排序,就可以得到按照X、Y 排序的结果集,如下:
(1, 5) (1, 2)
(2, 9) (2, 1) (2, 5)
(3, 3) (3, 7)
=====================
(1, 2)
(1, 5)
(2, 1)
(2, 5)
(2, 9)
(3, 3)
(3, 7)
这种算法的好处是显而易见的,特别是对大的数据集来说,这样会减少每次排序的数据量,这里可以通过一定的策略控制让每次排序的数据量更适应当前设置的work_mem。另外一方面,在PostgreSQL 的瀑布模型执行器中,我们可以不用全部数据的排序结果就可以得到部分结果集,非常适合带Limit 关键字的top-N 的查询。
当然,在数据库的优化器中,要远比上面的情况复杂的多。如果每个分组较大,分组数量较少的话,增量排序的代价会比较高。如果每个分组较小,分组数量较多的话,我们使用增量排序利用之前排好序的结果需要的代价比较小。为了中和两者的影响,PostgreSQL 13 中采用了2种模式:
- 抓取相对安全的行数不需要检查之前的排序键进行全排,这里的安全是基于一些代价的考虑。
- 抓取所有的行,基于之前的排序键上再进行分组排序。
PostgreSQL 优化器是优先会去使用模式1,然后启发式地使用模式2。
增量排序具体的使用方法以及开启关闭该功能的执行计划对比如下:
postgres=# create table t (a int, b int, c int);
CREATE TABLE
postgres=# insert into t select mod(i,10),mod(i,10),i from generate_series(1,10000) s(i);
INSERT 0 10000
postgres=# create index on t (a);
CREATE INDEX
postgres=# analyze t;
ANALYZE
postgres=# set enable_incrementalsort = off;
SET
postgres=# explain analyze select a,b,sum(c) from t group by 1,2 order by 1,2,3 limit 1;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------
Limit (cost=231.50..231.50 rows=1 width=16) (actual time=2.814..2.815 rows=1 loops=1)
-> Sort (cost=231.50..231.75 rows=100 width=16) (actual time=2.813..2.813 rows=1 loops=1)
Sort Key: a, b, (sum(c))
Sort Method: top-N heapsort Memory: 25kB
-> HashAggregate (cost=230.00..231.00 rows=100 width=16) (actual time=2.801..2.804 rows=10 loops=1)
Group Key: a, b
Peak Memory Usage: 37 kB
-> Seq Scan on t (cost=0.00..155.00 rows=10000 width=12) (actual time=0.012..0.951 rows=10000 loops=1)
Planning Time: 0.169 ms
Execution Time: 2.858 ms
(10 rows)
postgres=# set enable_incrementalsort = on;
SET
postgres=# explain analyze select a,b,sum(c) from t group by 1,2 order by 1,2,3 limit 1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=133.63..146.52 rows=1 width=16) (actual time=1.177..1.177 rows=1 loops=1)
-> Incremental Sort (cost=133.63..1422.16 rows=100 width=16) (actual time=1.176..1.176 rows=1 loops=1)
Sort Key: a, b, (sum(c))
Presorted Key: a, b
Full-sort Groups: 1 Sort Method: quicksort Average Memory: 25kB Peak Memory: 25kB
-> GroupAggregate (cost=120.65..1417.66 rows=100 width=16) (actual time=0.746..1.158 rows=2 loops=1)
Group Key: a, b
-> Incremental Sort (cost=120.65..1341.66 rows=10000 width=12) (actual time=0.329..0.944 rows=2001 loops=1)
Sort Key: a, b
Presorted Key: a
Full-sort Groups: 3 Sort Method: quicksort Average Memory: 28kB Peak Memory: 28kB
Pre-sorted Groups: 3 Sort Method: quicksort Average Memory: 71kB Peak Memory: 71kB
-> Index Scan using t_a_idx on t (cost=0.29..412.65 rows=10000 width=12) (actual time=0.011..0.504 rows=3001 loops=1)
Planning Time: 0.164 ms
Execution Time: 1.205 ms
(15 rows)
分区表增强
PostgreSQL 13 版本中对PostgreSQL中的分区表功能有多处增强,包括在多分区表中进行直接连接,以减少总的查询执行时间。分区表现在支持BEFORE关键字的行级触发器,并且现在一个分区表也可以通过逻辑复制的方式进行复制, 而不必像以前那个发布单个分区表。
其他
- 支持了带有OR选项或是IN/ANY选项的查询使用扩展的统计信息(通过 CREATE STATISTICS 创建),这样就可以得到更合理的查询规划和性能提升。
- 支持大数据集查询时,hashagg 使用磁盘存储(enable_hashagg_disk=on)。在之前的版本中,如果hashagg 使用的内存预测要大于work_mem,则不使用hashagg。
- 对jsonpath的查询增加了.datetime()函数, 它可以将日期或时间的字符串自动转换为对应的PostgreSQL日期或时间数据类型。
- 支持 gen_random_uuid() 内置函数生成随机的UUID,而不依赖外部插件。
数据库管理
并行VACUUM
PostgreSQL 13 版本中最令人期待的特性之一就是并行VACUUM。在之前的版本中,每个表的VACUUM 操作并不能并行,当表比较大的时候,VACUUM 的时间就会很长。在PostgreSQL 13中,支持了对索引的并行VACUUM,目前有很多的限制:
- 目前仅限于索引,每个索引可以分配一个vacuum worker。
- 不支持在加上FULL选项后使用。
- 只有在至少有2个以上索引的表上使用parallel选项才有效。
我们使用并行VACUUM 和12 版本进行了一个简单的对比,如下:
=================================PG 13 parallel vacuum===============================
postgres=# create table testva(id int,info text);
CREATE TABLE
Time: 2.334 ms
postgres=# insert into testva select generate_series(1,1000000),md5(random()::text);
INSERT 0 1000000
Time: 1448.098 ms (00:01.448)
postgres=# create index idx_testva on testva(id);
CREATE INDEX
Time: 364.988 ms
postgres=# create index idx_testva_info on testva(info);
CREATE INDEX
Time: 873.416 ms
postgres=# vacuum (parallel 4) testva;
VACUUM
Time: 114.846 ms
=================================PG 12 normal vacuum===============================
postgres=# create table testva(id int,info text);
CREATE TABLE
Time: 5.817 ms
postgres=# insert into testva select generate_series(1,1000000),md5(random()::text);
INSERT 0 1000000
Time: 3023.958 ms (00:03.024)
postgres=# create index idx_testva on testva(id);
CREATE INDEX
Time: 631.632 ms
postgres=# create index idx_testva_info on testva(info);
CREATE INDEX
Time: 1374.849 ms (00:01.375)
postgres=# vacuum testva;
VACUUM
Time: 216.944 ms
可以看出,PostgreSQL 13 要比12 版本VACUUM 速度有了很大的提升。但是,相对来说,做的不够彻底。不过。社区邮件中正在积极地讨论块级别的并行VACUUM,详见链接。
其他
- reindexdb 命令增加–jobs 选项,允许用户并行重建索引。
- 引入了“可信插件”的概念,它允许超级用户指定一个普通用户可以安装的扩展,当然,该用户需要具有CREATE权限。
- 增强数据库状态的监控,跟踪WAL日志的使用统计、基于流式备份的进度和ANALYZE指令的执行进度。
- 支持pg_basebackup 命令生成辅助清单文件,可以使用pg_verifybackup 工具来验证备份的完整性。
- 可以限制为流复制槽所保留的WAL空间。
- 可以为standby 设置临时流复制槽。
- pg_dump 命令新增了–include-foreign-data参数,可以实现在导出数据时导出外部数据封装器所引用的其他服务器上的数据。
- pg_rewind 命令不仅可以在宕机后自动恢复,并且可以通过–write-recover-conf选项来配置PostgreSQL备库。 支持在目标实例上使用restore_command来获取所需的WAL日志。
这几项功能大大提高了PostgreSQL 数据库的运维能力,尤其是pg_rewind 大大提高了可玩性,这里不再详细介绍,我们会在后面的文章中介绍这样的功能增强会带来哪些可能性的玩法。
安全性
PostgreSQL 持续提升安全方面的能力,新版本引入了以下几个特性以提高安全性:
- 用于强大的psql工具和很多PostgreSQL连接驱动的libpq库,现在新增了几项参数用于安全的服务器连接。引入了channel_binding的参数,可以让客户端指定通道绑定作为SCRAM的组成部分, 并且,使用一个含密码保护的TLS证书的客户端现在可以通过sslpassword参数来指定密码。PostgreSQL现在也支持DER算法编码的证书。
- PostgreSQL的外部文件封装器postgres_fdw现在也新增了几个参数来实现安全的连接,包括使用基于证书进行身份验证去连接其他数据库集群。 另外,非特权的帐号现在可以通过postgre_fdw直接连接另一个PostgreSQL数据库而不必使用密码。
其他亮点
- PostgreSQL 13 继续提升在Windows平台上的操作性,现在Windows平台上的用户也有了可以通过UDS通讯方式来连接PostgreSQL服务的选项。
- PostgreSQL 13文档中增加了术语汇总表,来帮助用户了解PostgreSQL和一些通用的数据库概念。同时对函数和表中的操作符的显示也进行了优化,以帮助提升在线文档和PDF文档的可阅读性。
- 用于性能测试的pgbench,现在支持系统用户表的分区操作,这样在对包含分区表的性能测试时更加容易。
- psql工具现在包括类似于\echo的\warn 指令用于输出数据,差别是\warn会将输出重定向至stderr标准错误的虚拟设备。现在用户在需要了解更多PostgreSQL指令时,使用-help选项会包含一个网络链接,指向:https://www.postgresql.org.
其他的PostgreSQL 13 的详细功能列表,见链接。
总结
虽然PostgreSQL 13 这次没有引入计划中的TDE 功能和zheap 功能,但是还是有很多亮眼的功能,包括B树索引的deduplicate 功能,并行VACUUM,hashagg 可以使用磁盘,支持pg_verifybackup 工具验证备份完整性,pg_rewind 支持配置成备库和restore_command 获取所需的WAL 日志。有兴趣的同学可以下载下源码,编译下,分析下自己感兴趣的特性的实现,说不定可以发现更好的想法。