X-Engine · 性能优化 · Parallel WAL Recovery for X-Engine
Author: 筱院
背景
数据库的Crash Recovery时长关系到数据库的可用性SLA、故障止损时间、升级效率等多个方面。本文描述了针对X-Engine数据库存储引擎的一种Crash Recovery优化手段,在典型场景下可以显著缩短数据库实例的故障恢复时间,提升用户使用感受。
当前面临的问题
X-Engine是阿里自研的基于LSM-tree架构的数据库存储引擎,对X-Engine的数据更新是将变更数据并行插入无锁内存表(MemTable),同时为了防止MemTable过大影响数据查找和宕机恢复的效率,系统会不定期将MemTable转换成不可修改的内存表(ImmutableMemTables),并将ImmutableMemTables整体Flush落盘;对无锁内存表的持久化通过WAL机制保证。
关于LSM-tree结构和X-Engine的数据分层存储机制,可以阅读文章:X-Engine 一条数据的漫游
X-Engine存储引擎的故障恢复需要读取所有WAL文件并重新生成所有ImmutableMemTables和MemTables,整体Crash Recovery流程分为以下两步:
- X-Engine存储引擎元信息回放
- WAL文件回放,恢复所有的ImmutableMemTables和MemTables到shutdown前状态
当前阿里云MySQL(XEngine)线上实例有异常宕机后重启缓慢的现象,通过对相关现场和线下试验分析,异常宕机时,通常有大量内存表未Flush落盘,因此在宕机恢复时需要进行WAL文件回放,这一操作占据了X-Engine宕机重启的绝大部分时间。结合现有工程实现分析,当前X-Engine的WAL文件回放逻辑主要有以下几个问题:
- 单线程恢复内存表,无法发挥多核优势
- 使用同步IO接口读WAL文件,等待磁盘IO耗时较多
- 恢复过程中存在过多将ImmutableMemTables Flush落盘操作,虽然可以释放被Flush的内存表,节省内存开销,但磁盘操作进一步加大了X-Engine存储引擎宕机重启的耗时
WAL Recovery性能优化方案
针对上述问题,我们制定了XEngine WAL Recovery的优化方案。总体思路如下:
- 由于X-Engine存储引擎的所有数据都是存储在线程安全的无锁内存表中的,该内存表支持多线程并发更新,因此可以将单线程恢复MemTable优化成多线程并行恢复,充分利用多核的优势,让整个宕机恢复过程并行起来
- 将同步磁盘IO改成异步IO,缩减读文件耗时
- WAL恢复过程中尽可能减少ImmutableMemTables的Flush落盘操作,只有在超过内存配置阈值时,为了防止数据库实例OOM,才会触发Flush逻辑。实际上如果数据库重启前后没有内存相关的配置变更,那么宕机重启过程应该几乎没有Flush操作。
总体设计
Parallel WAL Recovery的总体设计如下:
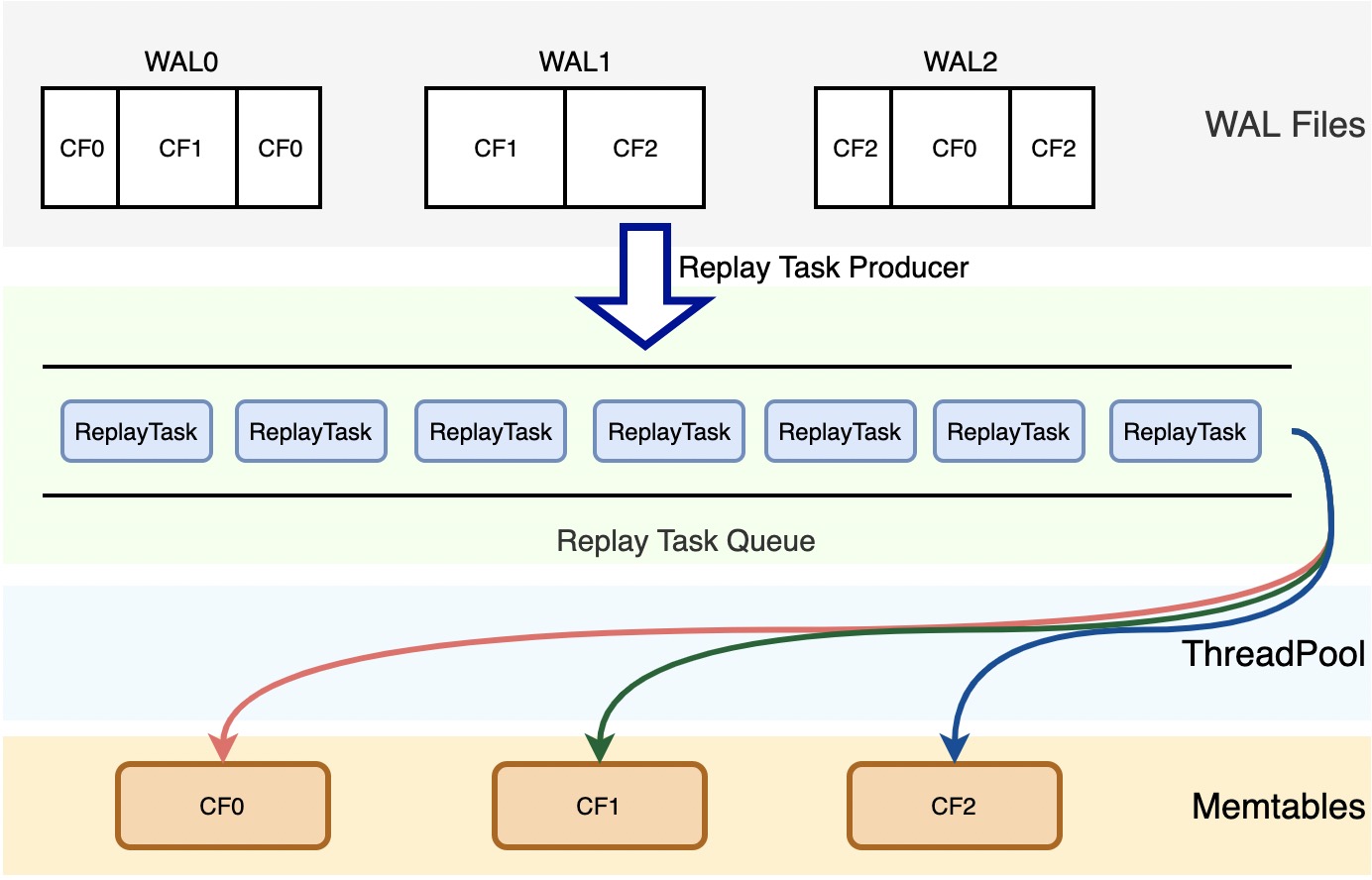
Recovery主线程可作为回放任务的生产者,通过aio接口读WAL文件,构造WAL回放任务存入回放线程池的任务队列中;
回放任务的主要成员是从WAL文件中解析出的一条完整WAL Record,里面包含了一批连续的数据更新记录,每个更新记录都有各自对应的全局序、操作类型和操作值等。
回放线程池中的回放线程从任务队列中获取回放任务并发更新内存表。
上述回放过程,我们通过一个回放线程池将读WAL文件操作和回放内存表操作完全并行起来,可以有效提升CPU利用率,降低回放时长。但是在实际设计过程中,还需要考虑以下几个问题:
- 宕机恢复过程中LSM-Tree的SwitchMemtable过程
- 2PC事务的正确回放
- 防御OOM
以下三节将具体阐述X-Engine的Paralle Recovery机制如何解决上述问题。
宕机恢复过程中LSM-Tree的SwitchMemtable过程
LSM-Tree的SwitchMemtable过程是X-Engine存储引擎中驱动数据由内存转移到磁盘的重要操作,具体逻辑是新建一个空MemTable,将当前正在更新的内存表标记为Immutable,后续数据库实例的新的更新操作将插入新建的MemTable中,已经被标记为Immutable的MemTable不可修改,等待一段时间后Flush落盘并从内存中释放。
SwitchMemtable发生在X-Engine的写入流水线中。触发SwitchMemtable的因素有很多,如单个MemTable内存超过一定阈值、单个MemTable中delete操作超过一定百分比、系统内存占用达到全局内存限制等。
在X-Engine的宕机恢复过程中,也需要根据一定条件触发SwitchMemtable,防止出现单个MemTable内存过大或全局内存超限等情况。触发SwitchMemtable的时间点无需和宕机前完全一致,但需要保证一个原则:SwitchMemtable发生的时刻,待Switch的内存表的最高Sequence之前的WAL Record已经回放完整,否则可能出现数据正确性问题,如下所示:
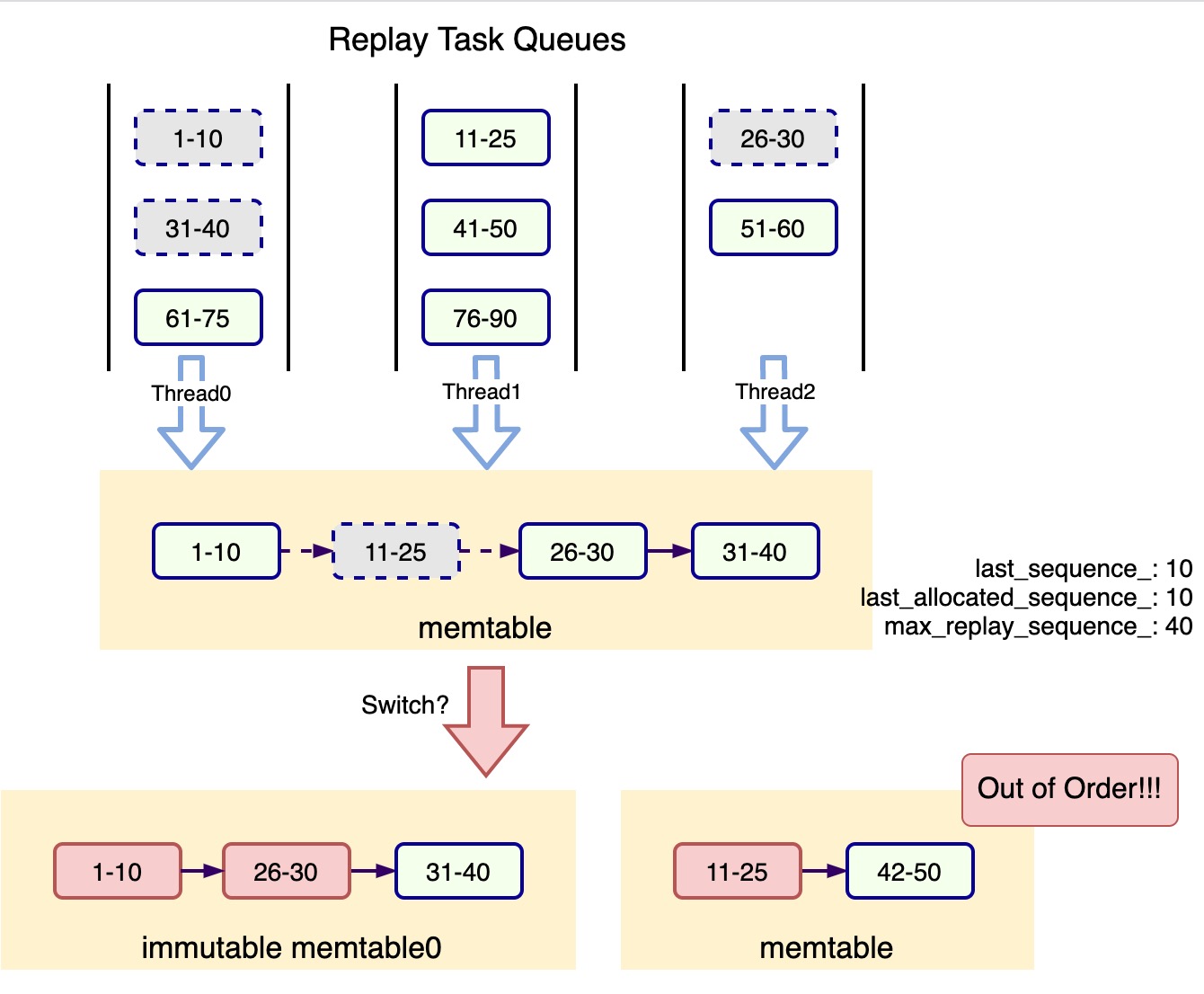
上图中,在Sequence(11-25)对应的WAL Record还未被Thread1插入MemTable时,MemTable被switch为Immutable MemTable0,Sequence(11-25)的WAL Record稍后被插入到新建内存表中,Immutable MemTable0和MemTable之间的WAL Record Sequence不再严格递增。LSM-Tree的读路径是先读MemTable,匹配不到对应的key再读ImmutableMemTable。假设Sequence_11和Sequence_26都是对同一个Key_A的修改操作,WAL回放完成后用户将获取到Sequence_11版本下的Key_A对应的value,最新的Sequence_26版本被隐藏,数据出现正确性问题。
解决方案
解决上述问题,并发WAL回放中的SwitchMemtable过程需要有一个全局barrier。
当回放主线程判断需要执行SwitchMemtable时,暂停任务队列中回放任务出队并等待所有并发回放线程执行完已经从任务队列中取出的回放任务,即等待上图中Sequence(11-25)对应的WAL Record被插入到memtable中后,才可以安全进行Switch;待SwitchMemtable过程结束后,回放主线程将通知回放线程池可以继续工作。
在并行回放过程中,回放主线程是照WAL Record的全局序将回放任务投递到任务队列中,因此只要回放线程池执行完从任务队列中取出的回放任务,就可以保证当前MemTable的最大Sequence之前的WAL Record已经回放完整。
同时,由于SwichMemtable需要在全局barrier中进行,频繁的SwtichMemtable操作将导致X-Engine的并发回放效率降低,因此需要调整并发回放过程中触发SwichMemtable的策略。
我们倾向于积攒一批SwitchMemtable任务后,在一个全局Barrier中完成所有的SwitchMemtable操作,以避免频繁地暂停回放线程池。目前在并发回放过程中触发SwitchMemtable需要满足以下三个条件之一:
- 系统中已经积攒了超过一定数量内存表的SwitchMemtable任务(默认3个)
- 某个内存表已经达到触发SwitchMemtable的条件阈值并等待SwitchMemtable超过一定时间(默认10s)
- X-Engine存储引擎全局内存占用超过阈值(此时不仅仅需要触发SwitchMemtable,还需要触发Flush落盘操作,将在防御OOM章节中介绍)
2PC事务的正确回放
X-Engine存储引擎提供了2PC事务接口,主要用于binlog和X-Engine引擎的原子性提交保证以及跨引擎事务的原子性提交保证。
2PC事务在X-Engine中的实现如下:
- prepare阶段向WAL文件中写入事务更新记录和对应事务的prepare日志
- commit阶段将事务数据更新到内存表中并在WAL文件中写入对应事务的commit事件
- 事务通过XID来进行标识
2PC事务在X-Engine的恢复流程实现如下:
- 根据事务的prepare日志在内存中构造对应事务的数据更新上下文,用XID来标识
- 在读取到对应XID事务的commit日志时,根据XID从内存中获取事务上下文并更新内存表
上述流程在X-Engine原有的串行回放流程中可以正常跑通,但在并行回放中存在问题,原因是并行WAL回放过程中无法确定同一个事务的prepare日志和commit日志的回放顺序,可能出现commit日志先被回放到,而此时内存中的事务上下文尚未构建的情况;
另外,X-Engine的2PC事务接口的XID由SQL层传入,X-Engine内部要求不允许出现XID重叠的情况,即不允许一个XID标识的事务未被commit又再次以此XID发起事务prepare;但允许XID重复利用,即已经prepare、commit完成的XID允许再次发起prepare,同样,上述机制在并行WAL回放中也存在问题:假设WAL文件中有如下记录(X-Engine中对2PC事务日志分配的全局序与下表中不完全一致,下表仅作为示例说明):
| Sequence | 操作类型 | 操作值 |
|---|---|---|
| 1 | BeginPrepare | null |
| 2 | Put | Key=a, Value=b |
| 3 | EndPrepare | XID=aabb |
| 4 | Commit | XID=aabb |
| 5 | BeginPrepare | null |
| 6 | Put | Key=c, Value=d |
| 7 | EndPrepare | XID=aabb |
上表中,XID为aabb的事务在序号3的记录中完成prepare,在序号4完成commit,在序号7又再次完成prepare,X-Engine的2PC机制允许这种情况发生。在Crash Recovery过程中,上述WAL正确的回放顺序是序号3对应的aabb事务被成功提交,<a, b>被插入到MemTable中,而序号7标记的事务由于没有commit日志需要等待SQL层裁决是否提交还是回滚。
但是在并行回放时,所有回放任务可能同时被多个线程并行执行,无法准确按照3、4、7的序号完成回放,那么可能出现如下乱序执行问题:
- 序号7的事务parepare日志先被回放,在内存中构造出事务上下文:Put(c, d)
- 序号4的的commit日志随后被回放,此时在内存中根据XID=aabb获取到的事务上下文是Put(c, d),<c, d>被插入到MemTable中
- 序号3标记的事务prepare日志在X-Engine宕机恢复完成后作为未决事务等待SQL层裁决
- X-Engine回放出现数据正确性问题
解决方案
常规的解决思路是根据XID进行hash,将相同XID事务的回放任务按序投递给同一个回放线程执行,但由于不同事务包含的更新数据量差异悬殊,不同回放线程容易产生负载不均的问题。X-Engine的并行WAL回放采用的解决方案如下:
- 同一个事务的prepare、commit乱序执行问题解决方案:如果某个事务的commit日志被先行回放,此时由于prepare日志暂未回放,事务上下文尚未构造,无法实际提交对应事务,那么在内存中标记对应XID事务已经被commit;一个事务的prepare日志被回放时,需要检查内存中的事务状态,如果发现事务已经被标记为commit,那么直接提交当前事务,根据构造出的事务上下文更新MemTable
- 同名事务的prepare、commit乱序执行问题解决方案:同名事务问题的本质实际上是WAL并行回放过程中无法准确根据XID识别出不同事务的prepare、commit日志记录。考虑到LSM-Tree的所有日志记录全局有序且唯一递增,可以利用XID+PrepareLogSequence来唯一标记一个X-Engine 2PC事务。X-Engine宕机恢复主线程在读取WAL Record后,需要解析出对应的XID和XID对应的Prepare日志全局序,回放线程根据XID+PrepareLogSequence来唯一标记一个事务的回放状态,以此规避同名事务问题。
防御OOM
在数据库实例重启前后内存配置不变的情况下,宕机恢复后OOM的情况不太可能发生,但为了防止异常情况的发生,依然需要在并行WAL回放过程中考虑规避OOM问题。
解决方案
在SwitchMemtable章节我们简述了X-Engine并行WAL回放过程中触发SwitchMemtable的策略,为了降低SwitchMemtable过程造成的回放暂停的频率,需要积累一批SwitchMemtable任务并在必要的情况下一次性完成所有switch。Recovery主线程在每次向线程池任务队列提交回放任务之前,都会判断当前全局内存用量是否已经达到指定阈值,如果是,那么强制暂停回放线程池,触发SwitchMemtable,然后对SwitchMemtable过程产生的ImmutableMemTable进行Flush落盘操作,并释放这部分内存使用,以此来避免MemTable占用内存过多导致的OOM。
性能测试
测试环境
CPU配置:Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz 16核64线程
内存配置:512G
数据库:MySQL 8.0.18
WAL回放线程数对回放性能的影响分析
使用dbbench工具灌入约7900万行X-Engine数据,产生25G X-Engine WAL文件(无2PC相关日志);X-Engine内存阈值100G(实际使用约25G),数据写入和重启过程中都没有触发SwitchMemtable或Flush落盘;该测试的目的是比对极致场景下WAL回放线程数对回放性能的影响。
测试结果如下:
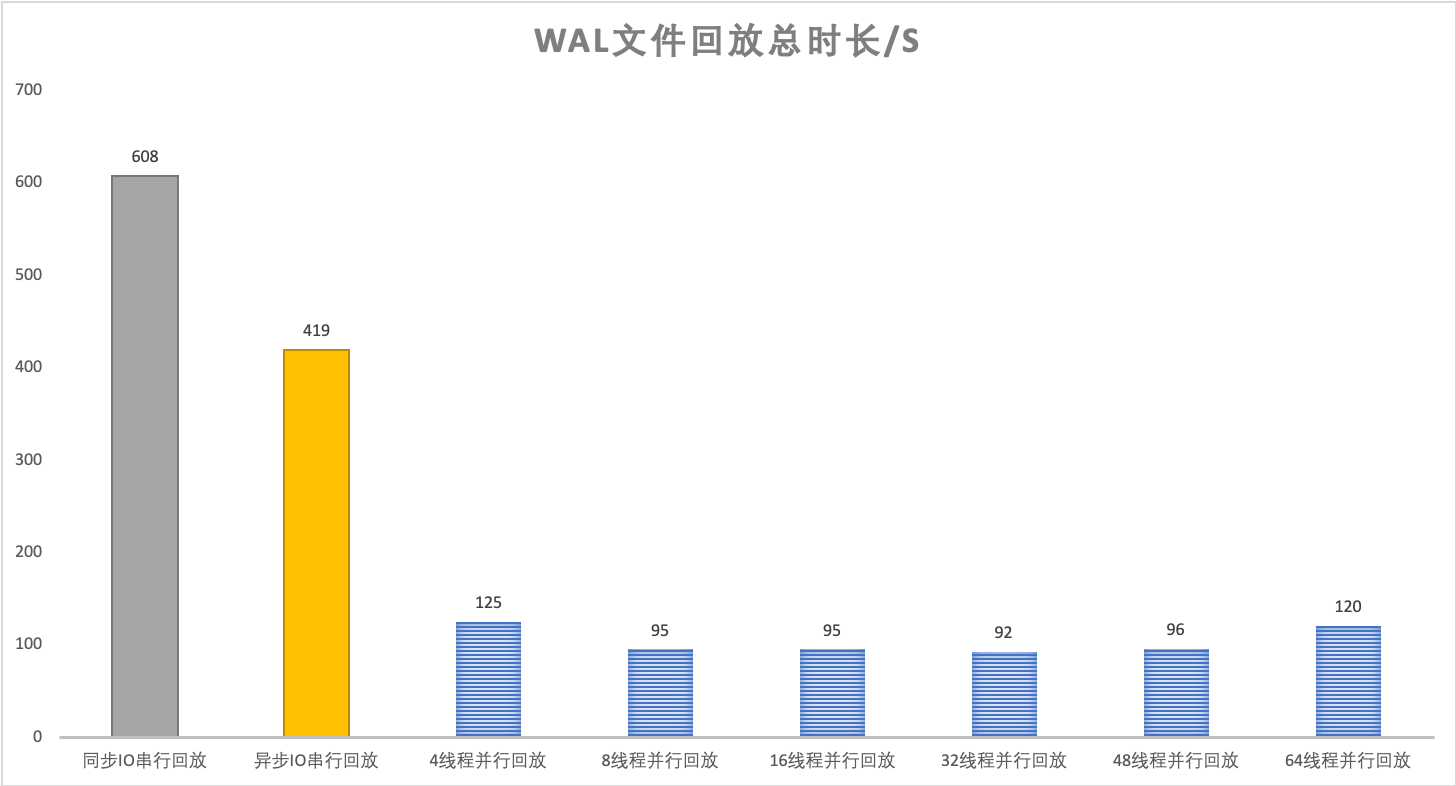
并行回放时间在150s以内,对比同步IO串行回放608s有4-5倍左右的性能提升、对比异步IO串行回放419s有2.5倍性能提升
CPU 64线程情况下,8-32并行回放线程可以取得比较好的性能
进一步分析:
4线程的性能瓶颈主要在多线程回放阶段
64线程的性能瓶颈主要在回放主线程读WAL Record及解析WAL Record阶段
典型场景WAL回放性能对比
使用TPCC工具灌入一定量数据(含2PC相关日志),在多种场景、多种数据库实例规格下比对同步IO串行回放、异步IO串行回放、异步IO并行回放三种回放方式的回放性能,测试结果如下:
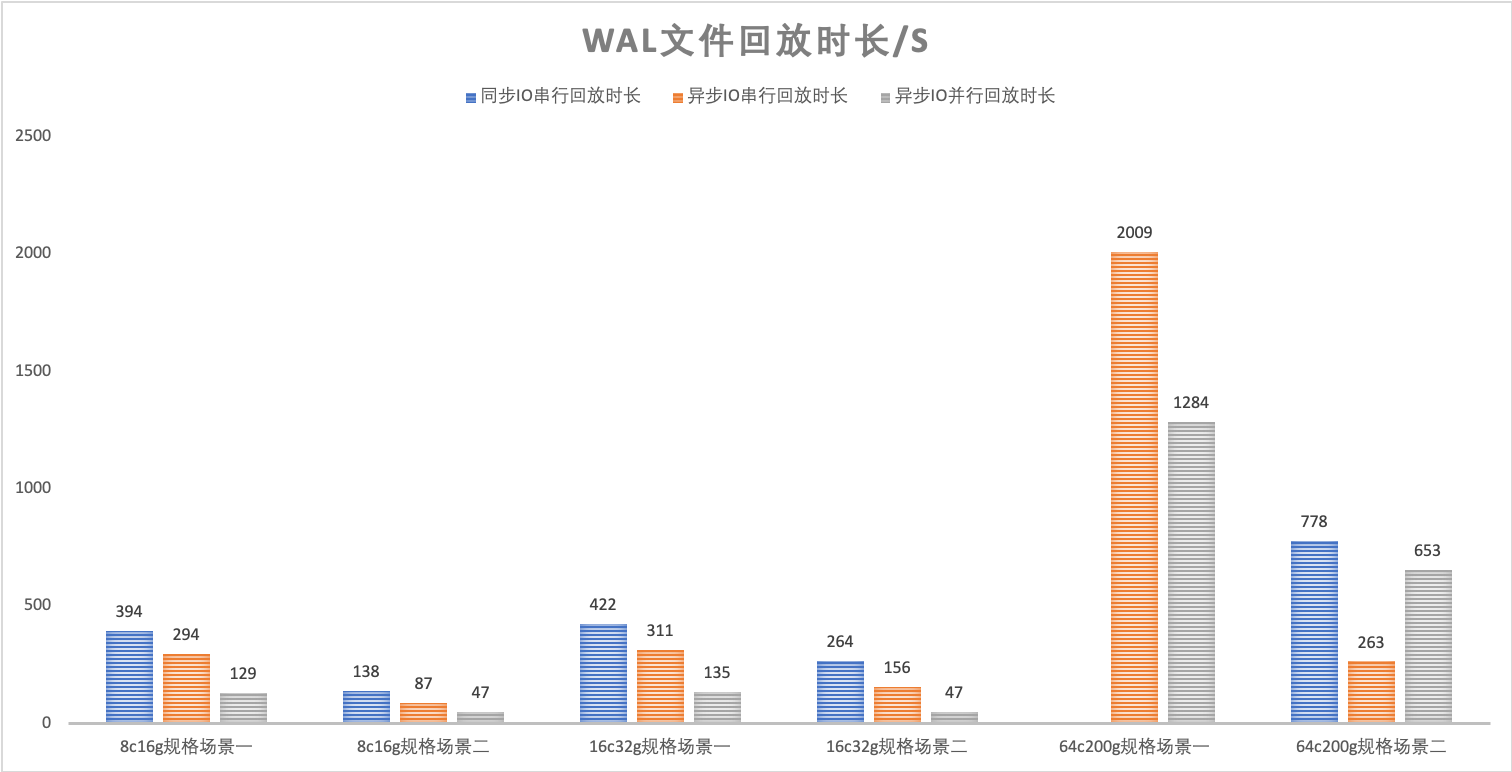
上述测试中场景一在灌数据过程中暂停Flush落盘,所有WAL Record都是有效日志,需要在回放过程中插入到内存表中,这将导致在宕机恢复过程中会触发多次内存表的SwitchMemtable和Flush落盘逻辑;
场景二指在灌数据过程中允许正常Flush落盘,测试仅部分WAL日志有效的典型场景下并行WAL回放和串行回放的性能对比,回放过程中可能触发SwitchMemtable和少量Flush落盘逻辑。
从上述实验结果可得,在大部分场景下,X-Engine的异步IO串行回放相比原始的同步IO串行回放有超过30%的性能提升,而并行WAL回放相比原始的串行回放有2-5倍的性能提升。
但在WAL文件积攒过多而绝大部分是无效日志的情况下,如上图中的64C200G规格场景一的测试中,并行回放性能表现反而不如异步IO串行回放,进一步分析得出导致性能退化的原因是绝大部分wal日志解析后无需插入内存表,因此并行回放的优势无法体现,同时由于并行回放在回放任务构造阶段需要进行更多的字符串解析、内存分配、字符串拷贝,向无锁队列提交task等步骤,逻辑比较复杂,因此耗时反而更高,后续将针对这种场景进行进一步优化。
测试结论
经过上述性能分析,在大部分场景下,X-Engine的并行WAL回放相比原始的串行回放性能上有2-5倍的性能提升。但在WAL文件积攒过多而绝大部分是无效日志的情况下,性能表现不如异步IO串行回放,这也是我们后续需要进一步解决的问题。
目前并行WAL回放的性能瓶颈主要在WAL文件解析和MemTable Flush落盘阶段。
后续工作
后续将针对并行WAL回放的性能瓶颈做进一步的优化迭代,如引入并行WAL文件解析机制、Crash Recovery过程中MemTable后台Flush机制等,以实现线上绝大部分场景可以在1分钟内重启数据库实例的性能目标。
同时X-Engine存储引擎的WAL并行回放也将应用在PolarDB(X-Engine)单机版和一写多读版本上,并针对PolarDB场景进行优化。