MySQL · 引擎特性 · 死锁检测
Author: jiangyi
旧版死锁检测
等待关系表达
在8.0.18以前,InnoDB的死锁检测机制是最常见的深度优先搜索(DFS)算法来搜索等待关系图
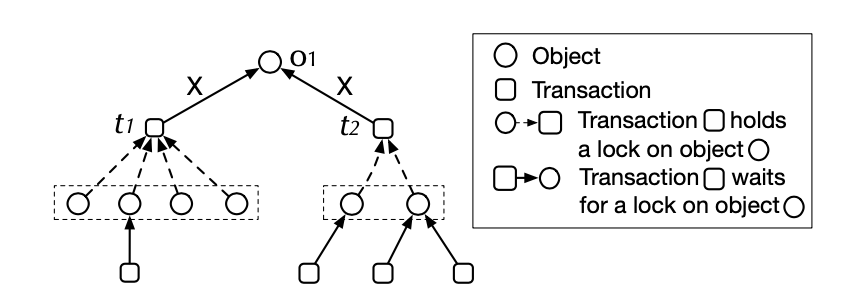 等待关系图如上图所示:
等待关系图如上图所示:
- 等待关系中的节点一种是等待对象(Object)例如行锁;另外一个是事务
- 等待关系中每一个对象都被事务锁持有,用虚线箭头表示
- 等待关系中每一个事务都在等待一个对象(例如行锁),用实现箭头表示
死锁检测
在死锁检测的时候,我们会持有lock_sys->mutex,然后对整个等待关系图进行DFS遍历,当发现等待关系图成环的时候,说明有死锁存在,我们根据事务优先级/undo大小/锁数量等因素选择一个事务进行回滚。 详细代码可参考 MySQL 8.0 DeadlockChecker类中相关实现,本文重点是讲新的死锁检测机制,因此老的机制参考以前的文档或者读者自己学习代码。
问题
老的死锁检测机制主要存在的问题是性能问题。 在DFS搜索等待关系图的时候,是会持有lock_sys->mutex这把大锁的,在lock_sys->mutex持有期间所有的新加行锁和释放全部会被阻塞。当出现大量锁等待的时候(例如电商热点行场景等),等待关系图会变的特别的大,导致每一次加锁DFS遍历整个等待关系图的时间变得非常的长,从而导致lock_sys->mutex竞争过于剧烈,引发大量线程等待lock_sys->mutex,从而导致数据库在此场景下雪崩。
新版死锁检测
等待关系表达
从上一段中我们知道,旧版的死锁检测的等待关系是包含了所有等待中的事务和其相关联的锁,从而导致在大量锁等待的时候,其等待关系十分的巨大。那么在死锁检测过程中,这么复杂的等待关系是否必要。 当死锁检测的成本远大于死锁的存在导致的等待成本时,这样的死锁检测机制就得不偿失了。新的死锁检测机制的理念是以较低的成本,确保在有限的时间内检测出死锁;而不保证每一次死锁检测都能检测出已经存在的死锁 因此新版死锁检测对等待关系图进行了裁剪,我们称为稀疏等待关系图。 在稀疏等待关系图中
- 等待关系中的节点都是一个事务,等待关系是事务和事务的直接等待
- 等待关系中一个事务只等待一个被等待事务
- 实际上一个事务有可能被很多事务等待,但是稀疏等待关系图中进行了裁剪,只显示最早的被等待事务
- 等待关系并非是一个全局一致的等待关系
- 只是一个乐观的快照,获取快照时并不持有lock_sys->mutex,仅持有lock_sys->wait_mutex
- 为什么不需要全局一致的,可以参考正确性部分
稀疏等待关系图的构造
- 稀疏等待关系保存在trx_t::blocking_trx这个原子指针中,通过版本号来保证其有效性
- 等待关系分别在等待事务加锁和被等待事务释放锁的时候被更新
- 特别的如果被等待事务释放锁,那么等待事务如果需要继续等待,则blocking_trx会被跟新成新的被等待事务
死锁检测
新的死锁检测机制变的比较轻量:
- 在持有lock_sys->wait_mutex的情况下,构造稀疏等待关系图,
lock_wait_snapshot_waiting_threads- 其实 lock_sys->wait_mutex 也不需要全程持有,只需要分段持有即可,其正确性我们在下一章讨论
- 对稀疏等待关系图进行DFS扫描,得到成环的子图,
lock_wait_find_and_handle_deadlocks - 对成环的子图进行有效性检测,
lock_wait_check_candidate_cycle- 确保其版本号是一致的
- 确保其还在继续等待
- 选择牺牲事务,并进行死锁处理(回滚)
lock_wait_choose_victim/lock_wait_handle_deadlock
正确性
这里首先要说明前提:
- 每一个非被阻塞的事务,需要在有限时间内被提交或回滚。(不能存在无限长的空闲事务)
我们用反证法来证明:
- 假设一个实际存在的死锁永远无法被发现
- 那么构成这个死锁的等待关系所有的边一定不会全部出现在稀疏等待关系图中
- 那么针对死锁等待关系的某一条边是 trx1(死锁图中的等待事务) 指向(等待) trx2(死锁图中的被等待事务)一定被另外一个出现在稀疏等待关系图中的trx1指向trx3(非死锁图中的被等待事务)锁覆盖,且trx3并没有在一个死锁关系中。
- 由上面的前提可知没有这样的trx3,(每一个非被阻塞的事务,需要在有限时间内被提交或回滚),因此我们可以得出,通过如上的死锁检测机制,实际存在的死锁一定会在有限的时间内被检测出来
负面案例
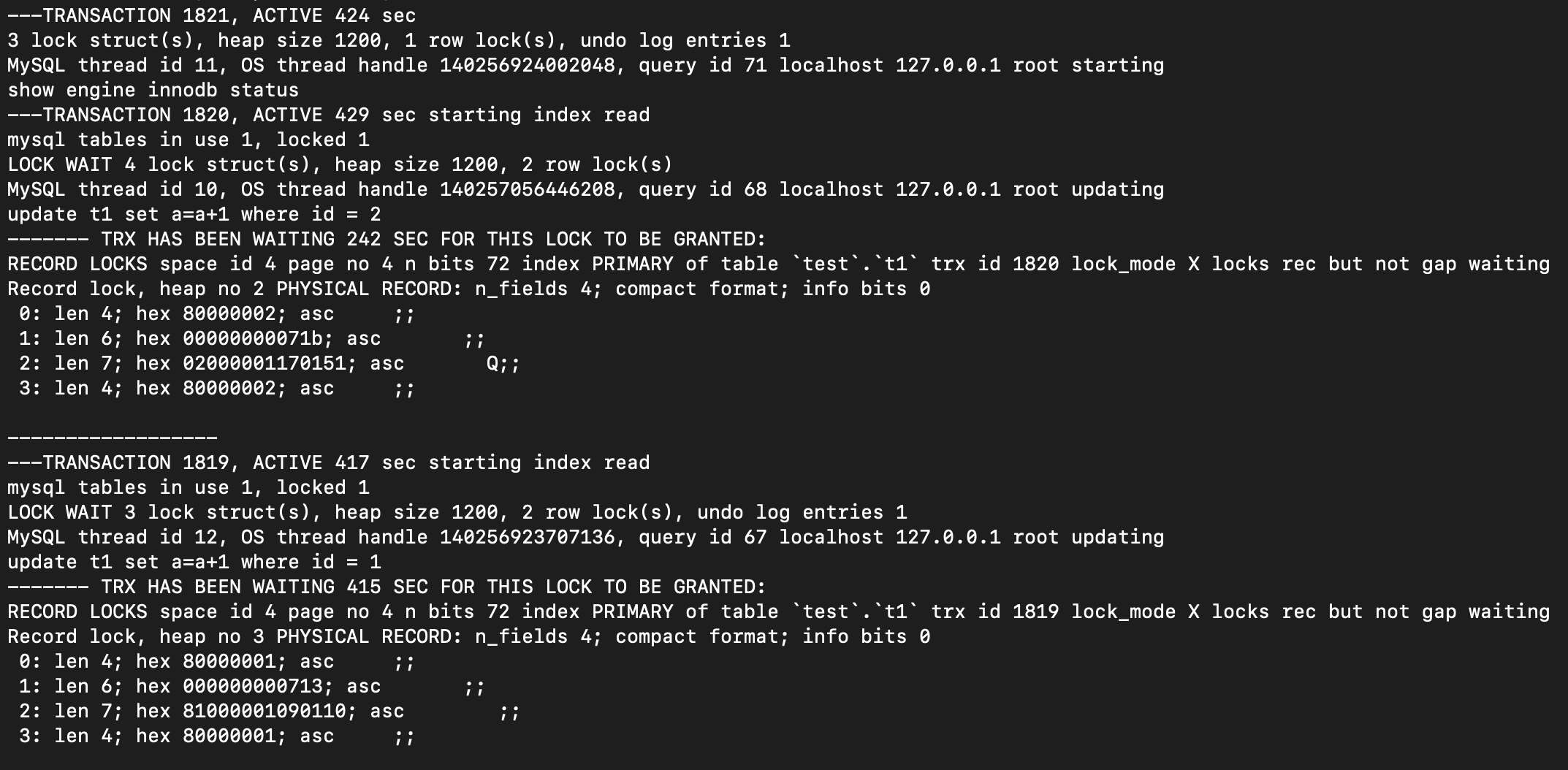
正常情况下,新的死锁检测机制可以有效提升在复杂等待关系下的死锁检测效率,毕竟相对于旧版机制,稀疏等待关系图的构建和检测都是非常轻量的。但是上文中也提了,因为等待关系的裁剪,有可能存在当一个事务其等待的锁被多个其他事务锁阻塞时(多个事务持有的是同一个对象的共享锁,或者是多个等待中的锁阻塞),稀疏等待关系图中该事务只会显示其中一个阻塞他的事务。因此可能出现某一次死锁检测时,真正引发死锁的等待关系并没有在稀疏等待关系图中出现,导致死锁并没有被检测出来。但是最终非死锁的锁等待会结束(被等待事务提交或者等待事务超时回滚等),死锁会被检测出来。 我这里构造一个出现死锁,但是新的死锁检测检测不出来的场景:
sql
connection1:
# init data
create table t1(id int not null primary key, a int);
insert into t1 select 1,1;
insert into t1 select 2,2;
# transaction1
begin;
select * from t1 where id = 1 lock in share mode;
connection2:
# transaction2
begin;
select * from t1 where id = 1 lock in share mode;
connection3:
# transaction3
begin;
update t1 set a=a+1 where id = 2;
update t1 set a=a+1 where id = 1; // 等待 被 transaction1 和 transaction2 阻塞
connection1:
# transaction1
update t1 set a=a+1 where id = 2; // 等待 被 transaction3 阻塞
此时:
- transaction1 持有 id=1 S LOCK,等待 id=2 X LOCK (被transaction3持有)
- transaction2 持有 id=1 S LOCK,无等待
- transaction3 持有 id=2 X LOCK,等待 id=1 X LOCK(被transaction1和transaction2持有)
transaction1 和 transaction3 发生实质性互相等待,出现死锁
但是在新的死锁检测的稀疏等待关系图中,只有2个等待事务,其中 transaction3 被 transaction2 等待,transaction1 被 transaction3 等待,没有发现死锁,因此不能解决死锁。其核心是稀疏等待关系图中 transaction3 被 transaction1 等待没有体现在稀疏等待关系图中。
效果
实际的重锁负载下的效果提升,大家就参考官方和自己的亲手测试啦,毕竟这不是一个PR文 :D