B+树数据库故障恢复概述
Author: 瀚之
前言
故障恢复是数据库中重要的组成部分,为了在故障发生时,有足够的信息将数据库还原到正确的状态,DB需要在正常运行过程中就维护一些冗余的数据,同时还要保证数据库的高效运行,充分利用硬件特性,支持高效的数据组织及访问模式。数据库可能遇到的故障主要包括三种类型:Transaction Failure,包括用户主动的事务Abort,以及并发控制中遇到的如死锁错误时,数据库对所选事务的回滚;System Failure:包括各种原因的进程意外退出或机器重启;Media Failure:由于硬件异常导致的数据永久性丢失。当遇到这些故障时,数据库需要保证
-
Durability of Updates:已经Commit的事务的修改,故障恢复后仍然存在;
-
Failure Atomic:失败事务的所有修改都不可见。
也就是我们常说的ACID中的A和D。其中Media Failure需要从备份恢复,大多数方案中其实是当作一种特殊的System Failure来处理的,因此本文主要关注Transaction Failue以及System Failure,也就是对事务Abort,以及Crash Recovery的支持。本文将从日志的写入,事务的回滚,故障恢复过程几个方面介绍B+Tree数据库在故障恢复功能上,面对的问题及做出的选择权衡。
故障恢复机制
之前的文章《数据库故障恢复机制的前世今生》[1],初步的介绍了磁盘数据库一路走来,其故障恢复机制的发展:Shadow Paging通过用额外空间记录修改后的Page内容,并在Commit时,通过原子的修改Directory元信息完成新旧Page的切换。其最大的问题在于Page内不能有事务并发;为了支持Page内的事务并发,自然地。可以采用在Log中记录修改信息的Logging的实现方式。这里出现了两个设计上的取舍权衡,一个权衡是要Redo Log还是Force机制(事务Commit之前其所有修改的Page必须落盘),另一个是要Undo Log还是Steal机制(事务Commit之前其修改的Page可以落盘)。
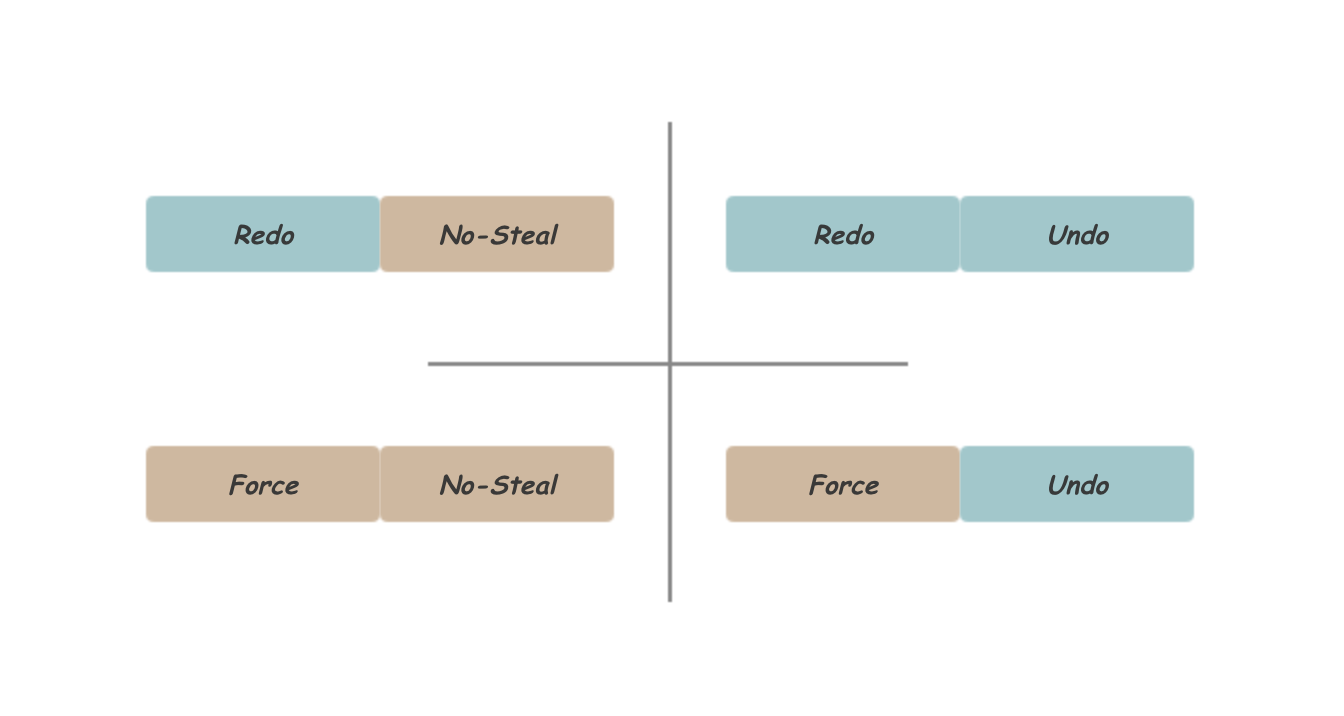
ARIES算法是在这一方向上的集大成者,其对上层应用提供了丰富灵活的接口,采用了No-Force加Steal机制,支持灵活的刷脏策略,将传统磁盘上的性能发挥到极致,从而成为传统磁盘数据故障恢复问题的标准解决方案。不过需要指出的是,这只是应对当前硬件环境的选择,在不同的硬件特性,或不同的数据库架构,甚至是一些特殊场景下,其他组合也可能有一席之地。
B+Tree并发控制
除了对硬件的适配,故障恢复机制的另一个需要考虑的就是对上层高效的并发控制及数据组织方式的支持。之前的文章《B+Tree数据库加锁历史》[2]中,介绍了在B+Tree这种对磁盘友好的数据组织方式下,并发控制如何逐步的提高其并发能力。其发展过程可以大体分为两个阶段,第一个阶段认为Page是最小的加锁单位,沿着减加少需要同时加锁Page数的思路,出现了可以提前释放祖先节点Lock的Tree Protocal,和避免在SMO中对父节点加锁的Blink Tree。之后第二个阶段将最小的加锁粒度从Page变成了Record,通过区分逻辑内容和物理内容,并对逻辑内容加Lock,物理内容加Latch,极大的提高了事务并发。
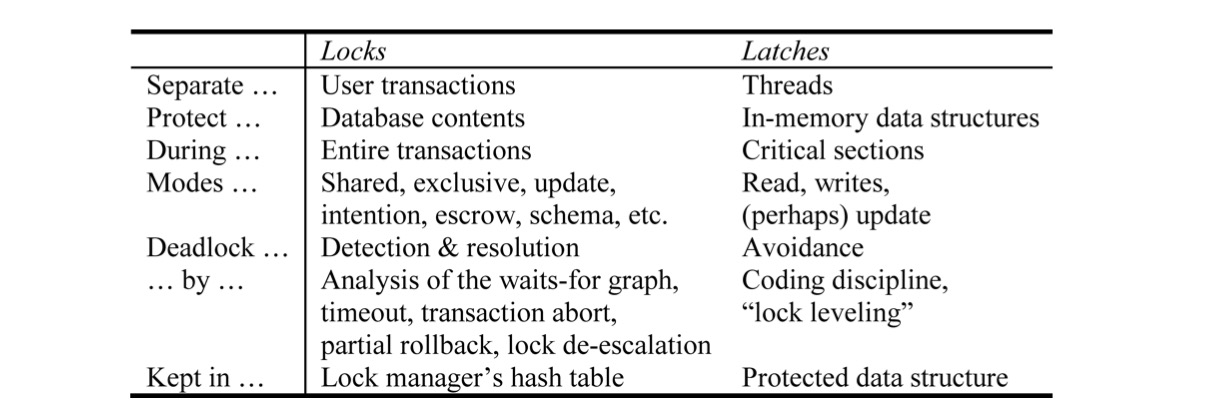
可以看出,为了支持这种Page内事务并发的并发控制机制,采用Logging的故障恢复策略是必不可少的,但只有这个还是不够,本文就将从Log的记录,事务的Abort,以及Crash Recovery等几个方向介绍在B+Tree数据库中的故障恢复机制设计思路及实现。
分层事务
B+Tree数据库将并发的粒度从Page变成Record来提高并发,其中最关键的一步其实是将数据库本身维护的物理结构跟事务看到的逻辑内容区分开来,从而可以在不同的维度分别做并发控制,加Lock或是Latch。如此一来,数据库整个的访问可以看成一个两层结构,上层操作用户可见的Record,用Lock保证事务之间的并发;下层操作维护数据的物理结构,用Latch保证线程之间的并发。下面以一个简单的事务为例:将某商品的库存量,分配给A,B,C两个经销商。
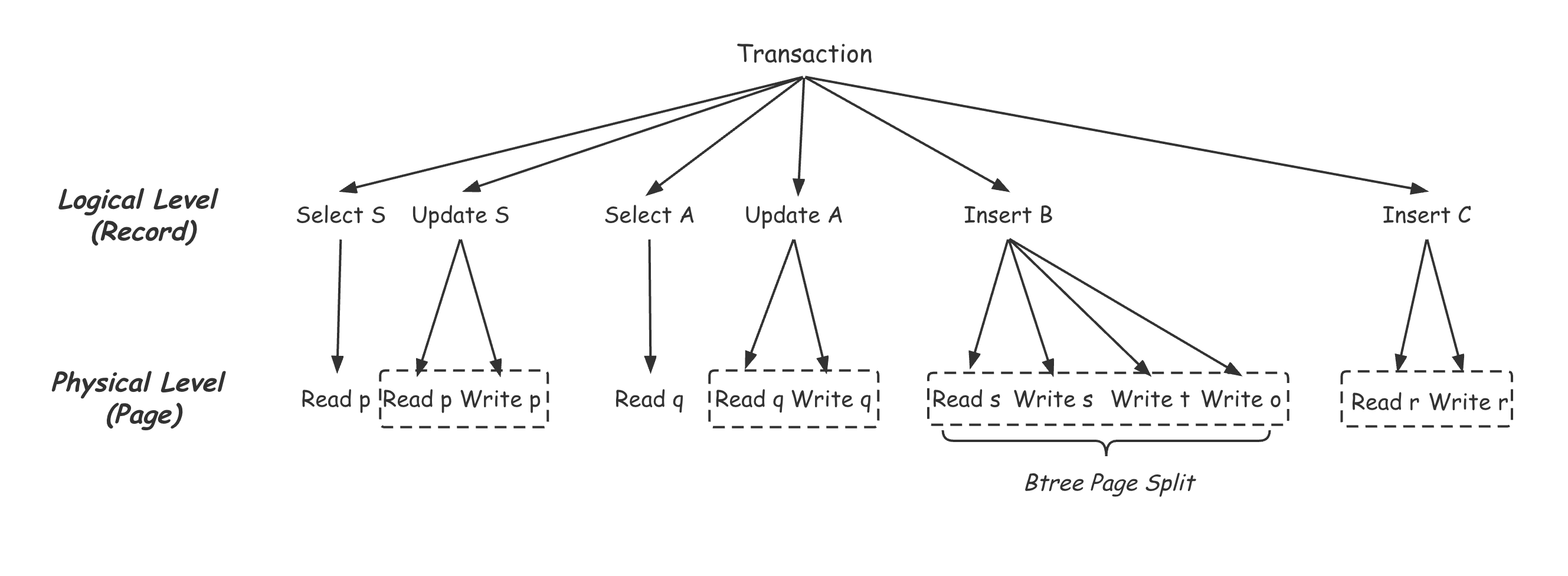
该事务需要首先检查商品总的库存量 S,减去本次分配额之后修改库存量 S,之后按比例分配给A,B,C三个经销商,其中B,C两个经销商是第一次收到该商品的销售任务,因此需要先进行记录的插入,而经销商A只需要修改商品的库存量即可。如上图所示,逻辑层也就是Record这一层的增删改查,最终会由物理层也就是Page上的修改实现。如上图中Logical Level对库存总量记录S的Update,最终由Physical Level的Read加Write该记录所在的Page p实现。其中,经销商B在插入新的Record时,造成了Page的分裂,导致了当前Page s、新增Page t、以及其父节点Page o的改动。可以看出,这样一个事务的操作最终由上图虚线框标识的四个独立的子操作组成。自然的,数据库需要保证这些子操作本身是一个不可分割的原子操作。《B+Tree数据库加锁历史》[2]中详细描述了如何用Latch来保证这些子操作在正常运行过程中的原子。但如果发生故障,如何保证恢复之后,这些子任务还能回到正确的状态呢?比如Insert C会不会存在一个非法的中间状态,也就是Btree结构的错误。
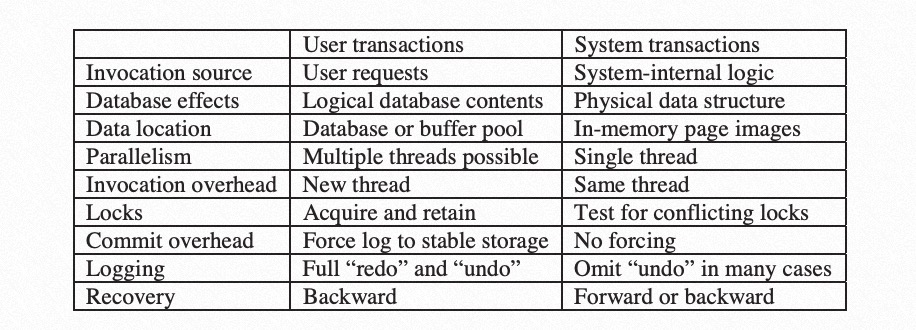
我们发现,这个需求其实跟我们前面提到的数据库的故障恢复需要保证的,Durable以及Crash Atomic是很类似的,因此可用类似事务的方式来实现。由于这些子任务是由数据库内部,而不是用户发起和感知的,因此我们称这些事务为System Transaction,对应的,用户发起的上层事务我们称为User Transaction。进一步对比这两种事务可以看出他们的区别和联系:
System Transaction
显而易见的区别包括:是由数据库内部发起而不是用户发起;保护的是物理数据而不是用户可见的逻辑数据;修改的Page可以先保证在内存,从而避免持有Latch等待IO;调用开销很小等。这里我们还是聚焦到System Transaction自己的故障恢复上来。按之前提过的,这里会面临两个权衡选择:是要Redo还是Force刷脏限制,要Undo还是No-Steal刷脏限制。考虑到System Transaction修改的数据相对更少,持续时间更短,并且提交时间可控,No-Steal带来的修改长时间在内存维护的问题似乎无关紧要,因此,大多数的设计中System Transaction采用Redo + No-Steal的实现方案,也就是要求修改的Page在对应的System Transaction提交之后才能落盘,从而避免记录对System Transaction的Undo Log。这样就得到了一个两层事务的结构:上层User Transaction可以发起一个或多个System Transaction来修改对应一个或多个Page;System Transaction保证一组操作的原子和持久化;并在完成对应的修改后就可以立即提交;System Transaction提交后,其修改的物理结构就是可以被其他事务看到的了(但其怎么构造可见的逻辑内容就是并发控制的事情了,比如MVCC);User Transaction层,采用Redo + Undo的故障恢复策略;而System Transaction采用Redo + No-Steal策略。
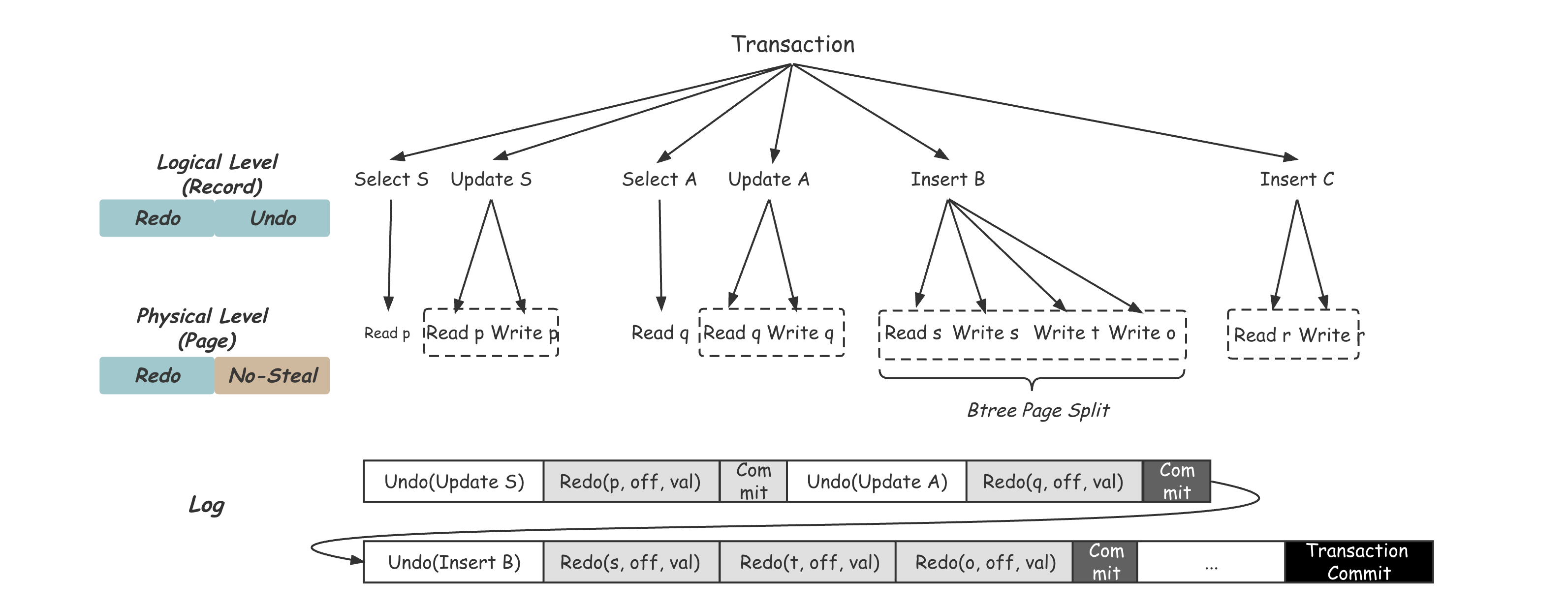
如上图所示,还以上面库存分配的事务为例,User Transaction会对自己的每个操作记录Undo Log,比如Update总库存量S操作的Undo Log这里记为_Undo(Update S)。之后通过System Transaction完成需要的原子操作,这个过程中System Transaction会写对应Page的Redo Log,以及自己的Commit标记,比如对Page p的修改的Redo Log在这里记为_Redo(p, off, val)。最终当用户执行完所有的操作之后,发起事务的Commit,等待_Transaction Commit_标记落盘后返回Commit成功。对这些Log的使用会在之后的Crash Recovery章节详细讲述。除此之外,在刷脏约束方面:
-
按照Write Ahead Log的要求,Page的落盘需要再对应Undo Log之后;
-
因为System Transaction的No-Steal策略,Page的落盘又需要在对应的System Transaction的Commit标记之后。
综上所述,Page的落盘需要在对应的每一个子操作的Undo及其System Transaction的Redo之后,但跟Transaction Commit标记的落盘顺序无关。
事务回滚
在上面的例子中,假设该事务在完成对经销商B的库存分发后,发生死锁或者用户放弃,需要回滚该事务。为了保证User Transactiom的Atomic,需要将该事务的所有修改还原,但在这种分层事务的实现中,System Transaction已经提交,其修改的Page已经可以被其他事务可见,甚至Record所在的Page都由于SMO发生了变化,不能简单的通过覆盖Page或Record的历史镜像来完成回滚。因此,就需要在User Transaction操作Record这一层,对之前的修改做逆操作,比如用Delete操作完成对Insert的回滚,用Increase操作完成对Decrease操作的回滚,这个逆操作同样需要发起新的System Transaction来完成。回滚的顺序跟当时执行的顺序相反,如下图所示,Rollback过程依次发起了Delete B,Update A及Upcate S操作,来逆序还原之前Insert B,Update A, Update S的写入:
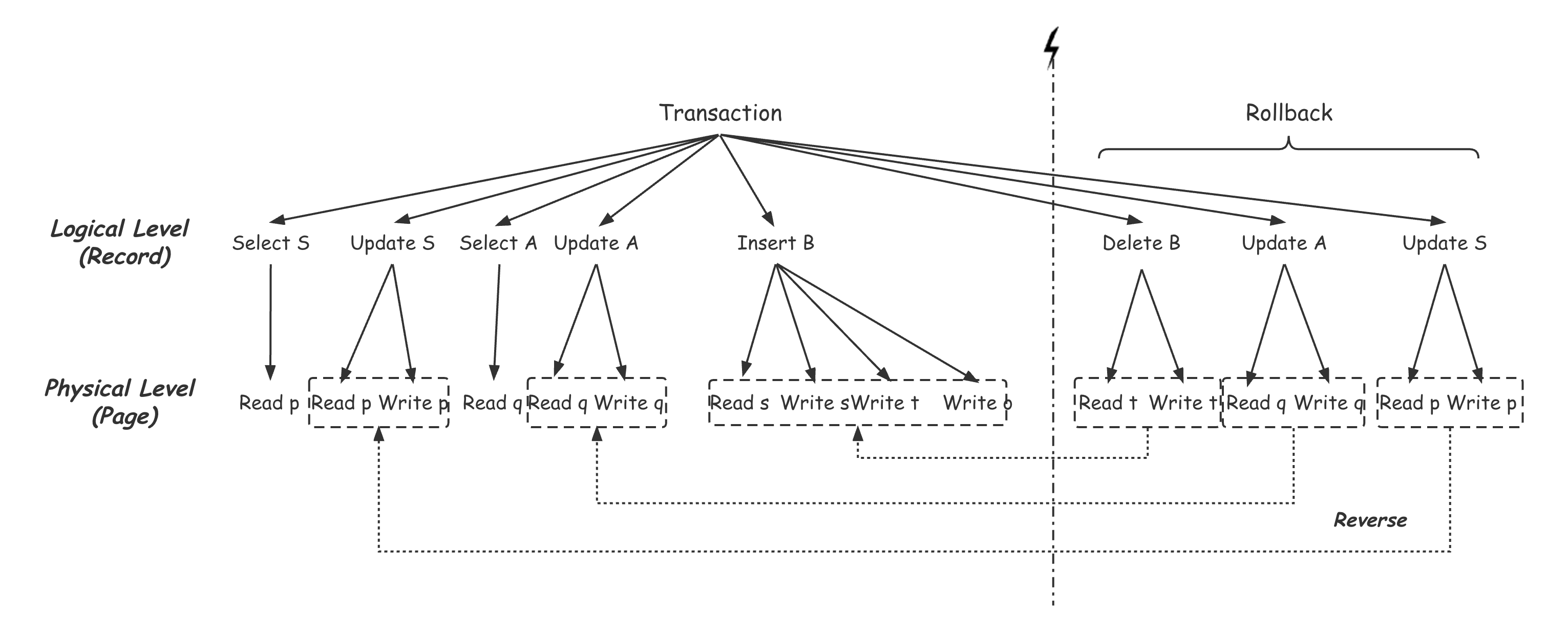
逻辑回滚
从上面的回滚过程可以看到一个有趣的现象,事务回滚后,其对数据库的修改其实没有完全消失,比如Insert B造成的Page Split,其逆操作Delete B并没有合并Page s和Page t,而是直接在Page t上对Record B进行删除或标记Ghost Record。这其实是我们乐意看到的,因为一旦Page Split完成,这个结果就是其他事务可见的,其他事务就可能在新的Page上写入数据,那么事务回滚时撤销这个Page Split就是不可能的。归根结底,还是因为SMO操作属于纯粹的物理数据修改,类似的情况还有文件Extend,标记Ghost Record等,这些修改都不应该被回滚事务撤销。其实在分层事务之前,对于这个需求就有过很多探索。 《Guardians and Actions: Linguistic Support for Robust, Distributed Programs》[3]提出的Top Action允许事务发起另外一个嵌套事务来专门处理像SMO这种物理结构的修改,当前事务需要等该嵌套事务提交后再继续后面的动作,这时由于该嵌套事务已经提交,原事务的回滚并不会对其造成影响。这个方案的问题在于发起一个新的事务实现较重甚至会和当前事务有加锁冲突。 之后《ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging》 [5]采用Nested Top Action来避免真正的发起新的事务。ARIES会首先预留一段Redo空间给SMO (Structure Modification Operations),避免有其他事务的Redo插入到中间,之后当对应的SMO操作完成后写入一个Dummy CLR记录,正常的CLR记录本身是在Recovery阶段写入来避免事务重复Undo的,这种记录会记录前一条需要Undo的日志位置,并在事务回滚时直接跳到这个位置去,从而避免中间这部分的Record的undo,如下图所示:
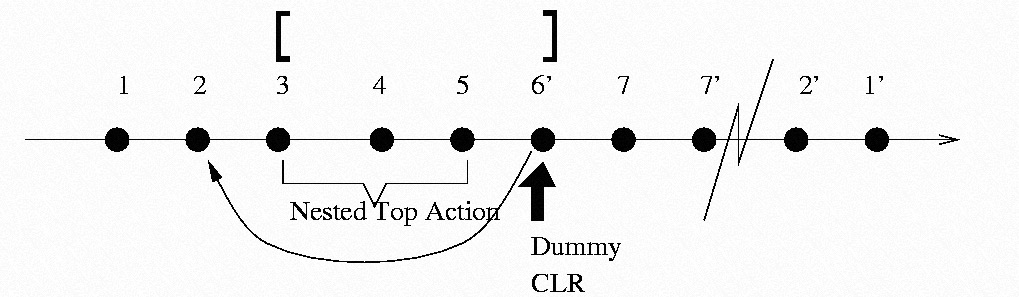
其实Nested Top Action已经很接近本文讲的System Transaction了,Dummy CLR也一定程度的起到了System Transaction的Commit标记的作用。而System Transaction更鲜明的区分了逻辑内容和物理内容,使得这一过程更加清晰。
Crash Recovery
当故障发生后,在进程重启时需要利用日志中的信息将DB还原到正确的状态,在上述分层事务的架构下,上层User Transaction正确运行的前提在于System Transaction能够保证其操作的原子及持久化。因此,Crash后自然会先进行System Transaction的Crash Recovery。按照上面的实现假设,System Transaction是没有Undo日志的,因为未提交的System Transaction是不会有任何数据落盘的,也就是No-steal策略保证了不需要Undo来回滚System Transaction的修改。那么,这时就只需要对所有已经提交的System Transaction的Redo Log做重放。对于Commit标记已经落盘的System Transaction,其对应的Redo Log都需要进行重放,而Commit标记没有落盘的,可以直接忽略,因为其所有对应的Page修改也一定没有落盘。 这时,其实User Transaction的Durable就已经满足了,接下来需要的就是对Crash发生前,未提交的User Transaction操作通过Undo中的信息进行回滚,来保证Crash Atomic。这一步就跟我们上一节中讲到的事务Abort同样的过程了。还是以之前的库存分发事务为例,假设在Insert B操作之后,发生进程崩溃,这时Update S,Update A,Insert B几个操作已经执行成功,但整个事务还没有Commit,因此正确的Crash Recovery应该将物理数据还原到Crash之前,并对该事务的操作进行回滚,其整个过程如下图,在Redo Phase中,数据库顺序根据Log中的Redo信息,将所有能看到System Transaction Commit标记的Redo Log进行重放。之后再Undo Phase中逆序对所有该事务的Undo Log发起逆操作,比如通过Delete B来回退Insert B,这个过程同样会发起新的System Transaction,同样会写入自己的Redo Log。
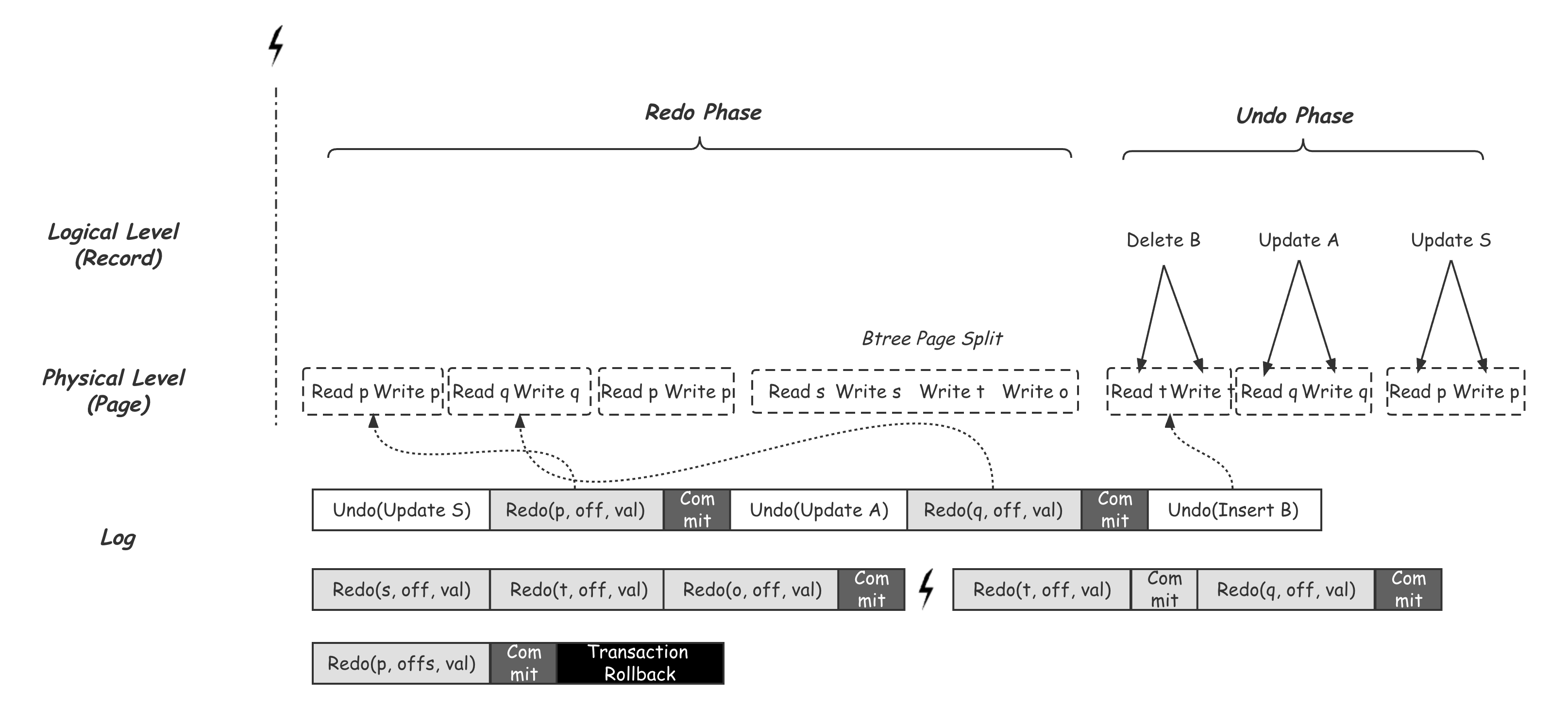
Logging
考虑到日志的生成是为Crash Recovery服务的,因此,在上面已经了解了Crash Recovery的过程之后,我们再来看看在这种分层事务的实现中需要怎样的日志。
Redo Log by System Transaction
可以看出,只有System Transaction会产生Redo Log,而这一层已经是针对物理层一个个Page的具体修改了。自然地,其产生的Redo Log也是Page Oriented的。除此之外,Page Oriented Redo还有一个很大的好处,就是在Crash Recovery做Redo重放时,针对每个Redo Record只需要考虑其在单个Page上的有序,而不需要关心其他Page,这就给并发的Redo重放带来极大的便利,从而可以支持更高效的故障恢复。 在针对某个Page记录Redo日志时,最简单的就是将其新的Page镜像,完整的记录在Redo中,但这无疑会带来巨大的日志写入和存储开销。进一步想到,可以只记录Page内修改的字节区间和这个区间内对应的新内容,这样相对于完整记录Page已经有了大幅的改善,但还不够,典型的,像Page内的碎片整理操作,按字节区间的方式还是需要记录几乎完整的Page内容。上述两种方式,其实都属于Physical Logging的实现,这种方式的优点在于重放效率高,问题在于空间占用大。与之对应的就是Logical Logging了,这种日志记录方式只需要记录对应的操作即可,比如上面的Page碎片整理操作,在Logical Logging中只需要记录一个Reorganize标记即可。因此,大多数现代数据库在Page内部都采用了Logical Logging的方式。当然,在真正的工业实现中,会有更多细节的权衡,比如一些小的修改可以采用Physical Logging的方式,甚至是整个记录Page镜像,比如Index Creation操作。综上所述,得到了一种比较优的日志实现方式:Physical to a page,logical within a page。也就是《Transaction Processing: Concepts and Techniques》中定义的Physiological Logging。
Undo Log by User Transaction
与Redo Log不同,Undo Log是在User Transaction中产生的,也是在这一层使用的,其本身是不感知对应的Page信息的。因此,Undo Log中记录的就是Page无关的逻辑内容。并且按照上面的讨论,利用Undo进行回滚时,是需要对之前的操作做逆操作的,这也决定了Undo Log采用Logical Logging更合适。
总结
本文总结了B+Tree数据库针对故障恢复的设计和面对的问题:
-
为了追求更高的事务并发度,B+Tree数据库区分了用户可见的逻辑内容和内部维护的物理结构,在并发控制上支持了Lock和Latch的分层,同时也在故障恢复上区分了User Transaction和System Transaction;
-
System Transaction由数据库内部发起,通常修改较少的一两个Page,提交时间可控,因此通常采用Redo + No Steal的策略,来避免写Undo Log;
-
在User Transaction需要回滚时,由于之前的System Transaction可能已经提交,其改变的物理结构,如新分裂的Page已经被其他事物使用。因此需要在User Transaction层的采取逆操作的方式进行回滚,逆操作同样需要发起System Transaction。
-
User Transaction的回滚不能回退物理结构的变化,比如Page分裂,这一点正好可以被System Transaction保证。
-
执行Crash Recovery时,需要先做System Transaction的故障恢复,由于其Redo + No Steal的实现,这里只需要重放其Redo Log。之后做User Transaction的Undo重放。
-
由于分层实现,Redo Log是由System Transction产生的,天然需要Page Oriented,而Page内日志为了减少日志量和存储开销,通常采用Logical的实现,因此Redo Log通常采用被称为Physiological Logging的方式。对应的User Transaction层产生的Undo Log采用Logical Logging的方式。
之后的文章中,会以InnoDB中的System Transaction:min-transaction及User Transaction的实现为例,来看看在工业实现中B+Tree数据库的故障恢复策略,其基本的实现思路都是符合本文讨论的。
参考:
[1] https://catkang.github.io/2019/01/16/crash-recovery.html
[2] https://catkang.github.io/2022/01/27/btree-lock.html
[4] [Weikum G. Principles and realization strategies of multilevel transaction management[J]. ACM Transactions on Database Systems (TODS), 1991, 16(1): 132-180.] (https://dl.acm.org/doi/abs/10.1145/103140.103145)
[7] Gray J, Reuter A. Transaction processing: concepts and techniques[M]. Elsevier, 1992.