PolarDB · 功能特性 · 嵌套子查询优化的性能分析
Author: zhilin
背景
嵌套子查询的性能问题一直是数据库优化的核心问题,原因也很明显,由于子查询的嵌套导致子查询被重复执行多次,尤其当主查询的数据量比较大时,由于子查询的嵌套迭代执行导致的性能问题就越发明显,因此优化器在优化过程中会根据子查询的特点,分别进行针对性的优化改写,提升查询的性能。下面我们就PolarDB对嵌套子查询的优化做一些详细的分析,让用户更深入理解PolarDB在性能优化方面的成就,让用户使用的更放心更安心。
包含聚集函数的子查询的优化方法
子查询优化的方法有很多,比如单值子查询的优化,SEMI-JOIN优化等,本文主要介绍的针对包含聚集函数的相关子查询的优化方法。下面是一个示例:
SELECT
SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM
lineitem,
part
WHERE
p_partkey = l_partkey
AND p_brand = 'Brand#55'
AND p_container = 'JUMBO CASE'
AND l_quantity < (
SELECT
0.2 * AVG(l_quantity)
FROM
lineitem
WHERE
l_partkey = p_partkey
)
LIMIT 1;
这是一个TPCH测试中一条件查询语句Query 17, 查询中包含了一个相关子查询,并且子查询中有聚集函数AVG,正常执行时,当主查询中lineitem表和part执行JOIN后产生的每一行数据都要将子查询执行一遍,然后才能做WHERE条件的过滤,得到最终的结果。显然,当主查询的行数非常大时,执行子查询的次数也自然很多,查询效率自然不高。
对此PolarDB提供了两种更好的优化方法,一种是首先对子查询按关联键进行分组执行聚集,将子查询转为一个Derived Table,然后将其提到主查询中,与主查询中的lineitem,part直接JOIN,避免子查询的无数次重复执行,实现性能优化的目的。这种优化方法可以简称为group by + Derived Table变换,下面我们通过改写的SQL来示意它的变换过程。
SELECT
SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM
lineitem,
part,
(SELECT
l_partkey as dt_partkey, 0.2 * AVG(l_quantity) as avg_quantity
FROM
lineitem
GROUP BY l_partkey
) dt
WHERE
p_partkey = l_partkey
AND p_brand = 'Brand#55'
AND p_container = 'JUMBO CASE'
AND p_partkey = dt.dt_partkey
AND l_quantity < dt.avg_quantity
LIMIT 1;
通过提前将lineitem按l_partkey分组,计算出每组l_partkey的平均值,然后和外层查询中的表进行JOIN,就可以直接得到对应的平均值,然后执行Where条件过滤即可得到最终结果。
除此之外,还有另外一种变换方法,是通过window function计算每组l_partkey的值,然后再使用Where条件过滤,得到最终的结果。这种优化方法可以简单为Window function + Derived Table变换,下面我们通过改写的SQL来示意它的变换过程。
SELECT
SUM(l_extendedprice) / 7.0 AS avg_yearly
FROM
(SELECT
l_quantity,
l_extendedprice,
(0.2 * AVG(l_quantity) OVER (PARTITION BY l_partkey)) as avg_quantity
FROM
lineitem,
part
WHERE
p_partkey = l_partkey
AND p_brand = 'Brand#55'
AND p_container = 'JUMBO CASE'
) win
WHERE
l_quantity < avg_quantity
LIMIT 1;
通过Window function将每组l_partkey的平均值计算出来,与group by + Derived Table变换不同的是,无需再多加一次JOIN,就可以直接过滤得到最终结果。
不同变换方式的性能分析
如下所示,对同一种SQL,有两种变换方式,那么到底应该选择哪一种变换方式呢?有没有可能不变换的性能更好呢?下面就这个问题进行详细的分析,首先进行一个测试,如下所示:
测试方法
创建2个表,一个表是小表,其主键是另一个表的外键,查询中会利用这个主外键做关联进行子查询的关联查询。
CREATE TABLE part (
p_partkey INT PRIMARY KEY
);
CREATE TABLE partsupp (
ps_partkey INT,
ps_supplycost DECIMAL(10,2),
INDEX i1 (ps_partkey)
);
我们在part表中插入100000条数据。在每一轮实验中,针对每一个p_partkey值,在partsupp表中插入不同factor(1,2,4,8,16,32)条数据来模拟不同关联条数的重复值的影响。通过过滤条件中不同的@selectivity(0.1~1)来模拟选择率的影响。
测试语句为一个类似Query 17的嵌套子查询:
SELECT COUNT(*) FROM part, partsupp
WHERE p_partkey = ps_partkey
AND ps_partkey <= 100000 * @selectivity
AND ps_supplycost >= (
SELECT AVG(ps_supplycost) FROM partsupp WHERE p_partkey = ps_partkey);
这里为了测试不同选择率对性能的影响,使用了一个@selectivity变量,它是一个session级的变量,并且为了测试选择率的影响,分别选择了两种模式,一种是这个影响选择率的条件在变换后不能下推到Derived Table中;另一种是这个影响选择率的条件在变换后可以下推到Derived Table中。 影响选择率的条件不能下推的Group by + Derived Table的变换示意如下:
SELECT COUNT(*) FROM
part, partsupp,
(select ps_partkey, AVG(ps_supplycost) as avg_supplycost
from partsupp group by ps_partkey) ps2
WHERE p_partkey = partsupp.ps_partkey
AND partsupp.ps_partkey <= 100000 * @selectivity
AND p_partkey = ps2.ps_partkey
AND partsupp.ps_supplycost >= avg_supplycost;
影响选择率的条件不能下推的Window function + Derived Table的变换示意如下: 在window function + Derived Table变换中,如果存在session变量不能下推的情况,PolarDB默认是不做Window function变换的,因为这种变换的性能可能会变差,测试中通过在子查询添加hint来强制Window function变换。
SELECT COUNT(*) FROM part, partsupp
WHERE p_partkey = ps_partkey
AND ps_partkey <= 100000 * @selectivity
AND ps_supplycost >= (
SELECT /*+ UNNEST(WINDOW_FUNCTION) */
AVG(ps_supplycost)
FROM partsupp
WHERE p_partkey = ps_partkey);
Window function + Derived Table变换后的查询:
SELECT COUNT(*) FROM
(
select ps_partkey, ps_supplycost, AVG(ps_supplycost) over(partition by ps_partkey) as avg_supplycost
from part, partsupp
where p_partkey = partsupp.ps_partkey
) win
where
win.ps_supplycost > win.avg_supplycost
AND ps_partkey <= 100000 * @selectivity;
影响选择率的条件可以下推的Group by + Derived Table的变换示意如下:
SELECT COUNT(*) FROM
part, partsupp,
(SELECT ps_partkey, AVG(ps_supplycost) as avg_supplycost
FROM partsupp
WHERE ps_partkey <= 100000 * 0.2
GROUP BY ps_partkey
) ps2
WHERE p_partkey = partsupp.ps_partkey
AND partsupp.ps_partkey <= 100000 * 0.2
AND p_partkey = ps2.ps_partkey
AND partsupp.ps_supplycost >= avg_supplycost;
影响选择率的条件可以下推的Window function + Derived Table的变换示意如下:
SELECT COUNT(*) FROM
(
select ps_partkey, ps_supplycost, AVG(ps_supplycost) over(partition by ps_partkey) as avg_supplycost
from part, partsupp
where p_partkey = partsupp.ps_partkey AND ps_partkey < 100000 * 0.2
) win
where
win.ps_supplycost > win.avg_supplycost;
测试结果如下所示:
相同选择率不同重复值的测试结果
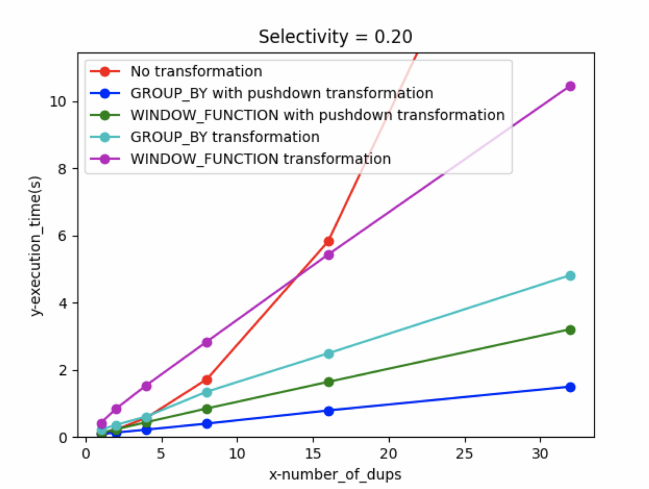
● 红色曲线是不变换的查询性能,受重复值的影响最大,当重复值大越多,性能越差。 ● 蓝色曲线是groupby变换,并且条件可以pushdown的场景,性能最好。 ● 绿色曲线是window变换,并且条件可以pushdown的场景,性能次优。 ● 浅蓝色曲线是group by变换,但条件不能pushdown的场景,性能又稍差。 ● 紫色曲线是window变换,但条件不能pushdown的场景,性能也不好很好,当重复值小于14左右,性能最差,之后略好于不变换的查询性能。
相同重复值不同选择率的测试结果
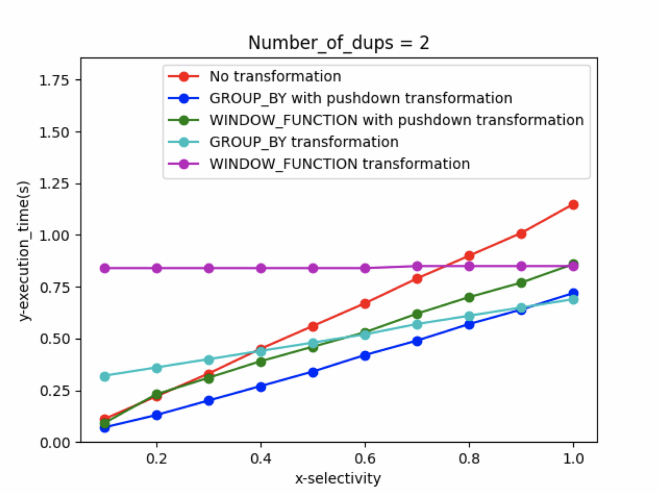
● 红色曲线表示不做任何变换的查询,性能会随着选择率的增长,性能越来越差,当超过80%时,最差。 ● 蓝色曲线表示groupby变换,并且条件可以pushdown,性能最好,由于测试精度问题,当选择率为100%时,应该和条件不pushdown的性能相当,此处显示会略好,只是2次测试之间的误差问题,因为本身执行时间就比较短,只有0.5s左右。 ● 绿色曲线表示window变换,并且条件可以pushdown,性能次优,随着选择率趋进于100%,和不能pushdown的性能相当。 ● 浅蓝色曲线表示groupby变换,但条件不能pushdown,性能在条件不能pushdown中是最优的。 ● 紫色曲线表示window变换,但条件不能pushdown,相比同样是window变换,但条件可以pushdown的性能相关比较大,当条件不能pushdown时,条件对性能的影响几乎可以忽略不记。
初步的性能分析结论
根据以上的测试和分析,发现这个性能结果出乎我们的意料之外,window变换很多情况下应该是最优的,但实际的测试结果和数据分析结果都与其相违背。而且对于TPCH中的Q2/Q17,window变换相比groupby变换有明显优势,到底问题出在哪里呢?因此后续对Q17又做了一些对比测试。
Q17的性能分析
为了解决上面测试出现的疑问,有必要对Q2/Q17的变换做深入分析,以解决上面结论中的问题。下面以Q17为例进行性能分析和测试。 测试数据集为10s,数据特点为对于partkey,lineitem中的重复值大约为30,比较大。另外Q17的选择率比较小,大约是0.11%。通过Explan analyze得到Q17执行过程中的性能数据:
Group by+Derived table变换
| -> Limit: 1 row(s) (actual time=12512.366..12512.366 rows=1 loops=1)
-> Aggregate: sum(lineitem.l_extendedprice) (actual time=12512.365..12512.365 rows=1 loops=1)
-> Nested loop inner join (actual time=12338.854..12511.773 rows=2644 loops=1)
-> Nested loop inner join (cost=40928.12 rows=58923) (actual time=0.198..153.232 rows=6688 loops=1)
-> Filter: ((part.p_container = 'JUMBO CASE') and (part.p_brand = 'Brand#55')) (cost=20305.00 rows=1980) (actual time=0.087..137.618 rows=222 loops=1)
-> Table scan on part (cost=20305.00 rows=198000) (actual time=0.027..94.947 rows=200000 loops=1)
-> Index lookup on lineitem using l_partkey_idx (l_partkey=part.p_partkey) (cost=7.44 rows=30) (actual time=0.052..0.063 rows=30 loops=222)
-> Filter: (lineitem.l_quantity < derived_1_2.Name_exp_1) (actual time=1.847..1.847 rows=0 loops=6688)
-> Index lookup on derived_1_2 using <auto_key2> (Name_exp_2=part.p_partkey) (actual time=0.001..0.001 rows=1 loops=6688)
-> Materialize (actual time=1.846..1.847 rows=1 loops=6688)
-> Group aggregate: avg(lineitem.l_quantity) (actual time=0.263..12091.061 rows=200000 loops=1)
-> Index scan on lineitem using l_partkey_idx (cost=607940.30 rows=5953163) (actual time=0.239..10743.582 rows=6001215 loops=1)
Window function+Derived table变换
| -> Limit: 1 row(s) (actual time=170.197..170.197 rows=1 loops=1)
-> Aggregate: sum(derived_1_2.Name_exp_3) (actual time=170.195..170.195 rows=1 loops=1)
-> Filter: (derived_1_2.Name_exp_2 < derived_1_2.Name_exp_1) (actual time=165.699..169.697 rows=2644 loops=1)
-> Table scan on derived_1_2 (actual time=0.001..0.873 rows=6688 loops=1)
-> Materialize (actual time=165.696..168.067 rows=6688 loops=1)
-> Window aggregate with buffering (actual time=144.326..162.817 rows=6688 loops=1)
-> Sort: <temporary>.l_partkey (actual time=144.243..145.376 rows=6688 loops=1)
-> Stream results (actual time=0.229..142.414 rows=6688 loops=1)
-> Nested loop inner join (cost=40928.12 rows=58923) (actual time=0.226..139.011 rows=6688 loops=1)
-> Filter: ((part.p_container = 'JUMBO CASE') and (part.p_brand = 'Brand#55')) (cost=20305.00 rows=1980) (actual time=0.109..121.276 rows=222 loops=1)
-> Table scan on part (cost=20305.00 rows=198000) (actual time=0.071..78.989 rows=200000 loops=1)
-> Index lookup on lineitem using l_partkey_idx (l_partkey=part.p_partkey) (cost=7.44 rows=30) (actual time=0.062..0.072 rows=30 loops=222)
为了分析简明方便,有如下的定义: 使用cnt表示需要读取表的行数,dup表示对于关联列l_partkey在表中的重复的平均行数,sel%表示选择率,则 不同阶段的COST如下表所示: | | group by + Derived Table变换 | window function + Derived Table变换 | | ——– | ——– | ——– | | io_cost | cnt(lineitem) + dup * cnt(part) * sel% + cnt(part) | cnt(part)+dup * cnt(part) * sel% | | join_cost | cnt(part) * sel% * dup | cnt(part) * sel% * dup | | win_cost | 0 | cnt(part) * sel% * dup | | avg_cost | cnt(lineitem) | 0 | | sort_cost | 0 | cnt(part)* sel% * dup | | mat_cost | cnt(lineitem) * 1/dup | cnt(part) * sel% * dup | | sum_cost | cnt(part) * sel% * dup * 40% | cnt(part) * sel% * dup * 40% |
其中,根据实际的数据估算,sel%=0.11,dup大约为30,40%为最终l_quantity < 0.8 * avg的选择率,TPCH原来为0.2,为了数据量更大,测试时调整为了0.8.
最终的性能分析结论
通过Q17的性能数据,可以发现window变换后的性能远远高于group by的变换,再经过详细的分析数据发现,写之前测试结论不同的原因主要有2点:
- Q17中的选择率非常低,大约在0.11%,而我们之前测试的至少都在10%左右,当选择率可以下推时,影响比较大。
- 另外一个更重要的一点是Q17在group by + Derived Table变换后的IO非常高,但在之前的测试中group by+Derived Table变换后IO并不是非常高,这也是导致性能相关较大的最主要的原因。通过深入分析发现,Q17的子查询中使用的是索引扫描,选择率的过滤条件在Q17中是通过filter来实现的,所以即使条件pushdown到子查询中后,仍需要扫描全表,而之前的测试是通过索引做range scan,并且ICP条件pushdown实现的,这样就导致在子查询中IO会大量减少,对group by+Derived Table变换的影响非常大,如果group by+Derived Table变换后不能使用索引来做range scan,条件也不能ICP下推,那么IO会非常大,是整个大表如lineitem表,或partsupp表的行数。而采用range scan+icp,就会直接是fitler过后的io,当filter很小时,IO就会非常小。 当使用windows变换时,首先是在小表part表中过滤,然后通过索引lookup大表lineitem表,这样IO只是part表的行数,以及过滤过的partkey对应在lineitem中的lookup的行数,因此io与lineitem的大小关系不大。
结论
通过以上的测试和性能分析结果,可以得出这样的结论,通过优化器的查询变换大多数情况下都可以提升性能,但在一些特殊场景下,无论是group by+Derived Table变换还是window+Derived Table变换有可能导致变换后的性能回退,不同变换的性能差异也比较明显,甚至不做变换反而性能是最优的。其中有几个因素对性能有比较大的影响:
- 影响外查询的选择率的条件,尽可能的下推到子查询中,当不能下推时,外查询的选择率越低,性能回退的可能性越高。
- 子查询中大表中包含关联列的重复值影响也很大,当重复值越大,变换后的性能提升越明显,这主要是因为提前做AGG聚集操作有利于减少中间结果;
- 子查询中是否可以将影响选择率的条件下推到存储层,当可以在存储层过滤大量数据时,group by+Derived Table变换的性能会更优,否则window + Derived Table变换的性能更优。
- 当条件不能pushdown到子查询中时,在重复值较小时,不变换性能更优;重复值稍大时,group by + Derived Table变换更优。当重复值超过某个阀值时,不变换的性能最差。
总之,对于包含聚集操作的嵌套子查询来说,采用什么样的变换方式需要根据实际的COST来决定,不同场景下数据集的特点相差很大,不同的场景下的查询选择率也相差很大,不能简单指定某个规则就应用于所有场景。